[kubernetes] 쿠버네티스의 controller(컨트롤러)란?

컨트롤러 매니저
1. 클러스터의 상태를 감시하고 현재 상태와 원하는 상태가 일치하도록 관리하는 작업
2. 컨트롤러 매니저는 컨트롤러(Replica controller, Service controller, Volume Controller, Node controller 등)를 생성하고 관리하는 역할을 한다.
컨트롤러 종류
1. 레플리케이션 컨트롤러(RC), 데몬 셋(DS),잡 컨트롤러
2. 디플로이먼트 컨트롤러
3. 스테이트 풀셋 컨트롤러
4. 노드 컨트롤러
5. 서비스 컨트롤러
6. 엔드포인트 컨트롤러
7. 네임스페이스 컨트롤러
8. 볼륨 컨트롤러
기본 오브젝트 종류
- pod, servicd, volume, namespace
- 기본 오브젝트는 컨트롤러 매니저에 의해 생성, 관리된다.
pod 란?
1. 파드는 배포의 최소 단위이다.
2. 파드는 하나 또는 여러 개의 컨테이너 그룹이다.
같은 파드의 컨테이너 그룹은 스토리지 및 네트워크를 공유하고 컨테이너들은 port로 구분하여 통신 가능하다.
3. 스케쥴러가 pod을 어떤 노드로 배포할지 결정한다.
4. 파드는 단일 파드 보다는 워크로드 리소스를 사용하여 여러 개의 파드를 생성하고 관리한다. 리소스에 해당하는 컨트롤러를 사용하여 파드는 장애 시 복제 및 롤아웃과 자동 복구를 한다. ( 디플로이먼트, 데몬 셋, 스테이플 셋 등)
파드 스토리지
1. 파드의 모든 컨테이너는 공유 스토리지 볼륨에 접근할 수 있다.
2. 컨테이너가 데이터를 공유할 수 있다.
3. 영구 데이터를 유지하도록 허용한다.
파드 네트워킹
1. 파드에는 고유한 IP 주소가 할당된다.
2. 파드의 모든 컨테이너는 IP 주소와 네트워크 포트를 포함하여 네트워크 네임스페이스를 공유한다.
3. 파드 내의 컨테이너들은 IP 주소와 포트 공간을 공유하며, localhost를 통해 서로 통신할 수 있다.
4. 다른 파드에서 실행되는 컨테이너와 상호 작용하려는 컨테이너는 IP 네트워킹을 사용하여 통신할 수 있다.
5. 파드 내의 컨테이너는 시스템 호스트명이 파드의 이름과 같다.
컨테이너에 대한 특권 모드
1. 파드의 모든 컨테이너는 보안 콘텍스트에 있는 privileged 플래그를 사용하여 특권 모드를 활성화할 수 있다.
2. 특권은 네트워크 조작이나 하드웨어 장치 접근과 같은 운영 체제 관리 기능을 사용하려는 컨테이너에 부여한다.
파드의 수명
1. 파드는 임시적이다. 파드가 생성되고 삭제될 때까지 해당 노드에서 실행된다. 만약 노드가 종료되면, 해당 노드에 스케줄 된 파드는 타임아웃 기간 후에 삭제되도록 스케줄 된다.
2. 파드가 스케줄링된 노드가 실패하면, 파드는 삭제된다.
파드는 리소스 부족 또는 노드 유지 관리 작업으로 인해 축출되지 않는다. 쿠버 네티스는 컨트롤러라 부르는 하이-레벨 추상화를 사용하여 상대적으로 일회용인 파드 인스턴스를 관리하는 작업을 처리한다.
3. 노드에 이미 스케줄링된 파드가 다른 노드로 사용 중인 상태 그대로 스케줄 되지는 않는다. 새롭게 배포될 뿐이다.
4. 스테이트 풀셋을 사용한다면 파드는 이름은 같지만, UID가 다른, 거의 동일한 새 파드로 배포할 수도 있다.
컨테이너 재시작 정책
1. 파드의 restartPolicy 필드: Always, OnFailure, Never이다. 기본값(Always)
2. restartPolicy는 파드의 모든 컨테이너에 적용된다.
3. restartPolicy는 동일한 노드에서 kubelet에 의한 컨테이너 재시작만을 의미한다.
4. 파드의 컨테이너가 종료된 후, kubelet은 5분으로 제한되는 지수 백오프 지연(10초, 20초, 40초, …)으로 컨테이너를 재시작한다. 컨테이너가 10분 동안 아무런 문제 없이 실행되면, kubelet은 해당 컨테이너의 재시작 백오프 타이머를 재설정한다.
5. 파드에서 컨테이너를 다시 시작하는 것과 파드를 다시 시작하는 것은 다른 의미이다. 파드의 재시작은 파드의 재배포로 새 파드가 실행된다.
yaml이란?
- 쿠버 네티스에서 pod를 만들기 위해서는 yaml문법을 통해 만들어진 yaml 파일이 필요하다.
- yaml은 사람이 읽을 수 있는 데이터 직렬화 언어이다.
yaml 문법
1. 들여 쓰기 구분: 공백 문자를 이용한 들여 쓰기로 구조체를 구분한다. 같은 상위 계층을 가지는 자식 계층들은 들여 쓰기가 정확히 일치해야 한다. 각 계츠은종속적이기 때문에 들여 쓰기가 틀리게 되면 오류가 발생한다.
1-2. 들여 쓰기는 탭키를 사용하지 않고 space로 구분한다.

2. 배열 정의

3. 데이터 정의는 key:value형식으로 정의한다.
반드시 : 다음에는 빈칸을 사용한다. 예) app: test 1

4. 주석

5. 요구되는 필드 (yaml에 들어가야 하는 필드)
| 정의 | 의미 | 예 |
| apiVersion | 오브젝트 버전 | v1, app/v1, networking.k8s.io/v1, autoscaling/v1, rbac.authorization.k8s.io............................... |
| kind | 종류 | Container, Pod, ReplicationController, Endpoints, Service, ConfigMap, Secret, PersistentVolumeClaim...................... |
| metadata | 메타데이터 | name과 label, annotation(주석)으로 구성 |
| spec | 상세 명세 | 리소스 종류마다 다름 |
apiVersion - 오브젝트를 생성하기 위한 쿠버 네티스 API 버전
kind - 생성하고자 하는 오브젝트의 종류
metadata - 이름 문자열, UID, 네임스페이스를 포함하여 오브젝트를 유일하게 구분 지어 줄 데이터
spec - 오브젝트에 대해 어떤 상태를 의도하는지 오브젝트 spec에 대한 정확한 포맷은 모든 쿠버 네티스 오브젝트마다 다르다. 파드에 대한 spec 포맷은 PodSpec v1 Core에서 확인할 수 있고, 디플로이먼트에 대한 spec 포맷은 DeploymentSpec v1 apps에서 확인할 수 있다.
yaml 파일 작성 예) label 작성과 annotation 사용
apiVersion: v1
kind: Pod
metadata:
labels:
security: zone2
color: blue
name: test5
annotations:
kubernetes.io/change-cause: "test rolling update version 1:1"
user: "you suye"
date: "2021-09-24"
spec:
containers:
- image: hewon16/image1:1
name: test5
ports:
- containerPort: 8080
protocol: TCP
레이블
1. 레이블은 오브젝트의 특성을 식별하는 데 사용된다.
2. 레이블은 오브젝트를 생성할 때에 붙이거나 생성 이후에 붙이거나 언제든지 수정이 가능하다.
3. 키는 고유한 값으로 오브젝트 내에서 유일해야 한다.
레이블 키가 해당 리소스 내에서 고유하다면, 하나 이상의 레이블을 가질 수 있다.
4. “키”: “값”으로 구성한다.
/로 구분되는 선택한 접두사와 이름 2개의 세그먼트가 있다.
kubernetes.io/와 k8s.io/ 접두사는 쿠버 네티스의 핵심 컴포넌트로 예약되어있다.
접두사를 생략하면 키 레이블은 사용자 정의 레이블이다. 예) app: test
5. 각 리소스는 레이블을 가질 수 있고, 특정 레이블을 가지고 있는 리소스만을 선택할 수 있다.
6. 레이블을 선택하여 특정 리소스만 배포하거나 업데이트할 수 있고 또는 레이블로 선택된 리소스만 Service에 연결할 수 있다.
어노테이션(annotation)
1. 쿠버네티스 시스템에서 필요한 정보들을 표시해 주기 위해서 사용한다.
2. 주석과 비슷하고 메타데이터 정보를 기록해 두는 데 사용한다.
3. 어노테이션은 레이블과 마찬가지로 키/값 쌍으로 구성된다.
4. 어노테이션은 오브젝트를 식별하고 선택하는 데 사용되지 않는다.(레이블과 다르다)
5. 어노테이션에서 사용되는 키는 쿠버 네티스 시스템이 인식할 수 있는 값들을 사용한다.
어노테이션 사용 예
- 쿠버 네티스에 새로운 기능을 추가할 때 사용된다.
새로운 기능의 필요한 API 변경이 명확해지고 쿠버네티스 개발자가 동의하면 새로운 필드가 도입되는 방식으로 관련 어노테이션은 사용 중지된다.
- 파드나 다른 API 오브젝트에 설명을 추가해놓으면, 클러스터 사용자가 개별 오브젝트에 관한 정보를 알기 쉽다.
Replication controller (RC) 레플리케이션 컨트롤러
1. Pod의 인스턴스가 항상 특정 개수로 작동하도록 관리할 목적 (레플리카수)
2. Pod의 레플리카 설정에 따라 자동으로 Pod의 인스턴스를 추가 제거한다.
3. 최근 버전에서는 레플리케이션 컨트롤러 대신에 디플로이먼트나 레플리카셋 사용을 권장한다.
4. 실행 중인 pod 목록을 지속적으로 모니터링 하여 특정 label selector와 일치하는 pod의 수가 replica 수와 일치하는지 항상 확인하고, 적으면 pod 템플릿에서 새 복제본을 만들고 많으면 실행중인 pod를 제거한다.
5. 레플리케이션 컨트롤러가 유지 관리하는 파드는 실패하거나 삭제되거나 종료되는 경우 자동으로 교체된다.
Replication controller(RC)의 3가지 요소
레이블 실렉터: RC의 범위에 있는 pod를 결정한다.
레플리카수: 실행할 pod의 의도(desired) 수를 지정한다.
파드 템플릿: 새로운 pod replica를 만들 때 사용한다.
파드 템플릿
1. 컨트롤러는 파드 템플릿에서 파드를 생성하고 사용자 대신 해당 파드를 관리한다.
2.파드 템플릿(PodTemplate)은 파드를 생성하기 위한 명세이며, 디플로이먼트, 잡 및 데몬 셋과 같은 워크로드 리소스에 포함된다.
3. 파드 템플릿을 수정하는 경우 이미 배포된 파드에는 영향을 주지 않는다. 파드 템플릿을 변경하는 경우, 해당 리소스는 수정된 템플릿을 사용하는 대체 파드를 생성해야 한다.
4. 파드 템플릿이 바뀌면, 컨트롤러는 갱신된 템플릿을 기반으로 신규 파드를 생성한다.
- 실습
Replication controller (RC) 생성
[root@master1 base]# cat test-rc.yaml
apiVersion: v1 #API 버전
kind: ReplicationController #RC의 매니페스트 정의
metadata:
name: test 1 #RC의 이름
spec:
replicas: 3 #파드의 개수 (인스턴스 수)
selector: #파드 실렉터로 RC가 관리하는 파드 선택
app: test 1 #RC가 관리하는 파드의 라벨이다. 생략도 가능( template가 해당 파드가 없으면 새 파드를 생성해준다.)
template: #새 파드에 사용할 파드 템플릿
metadata:
labels:
app: test1 #label은 app:test 1으로 위에서 선언한 RC의 label selector와 반드시 일치해야 한다.
spec:
containers:
- name: test1
image: hewon16/image1:1 #컨테이너의 이미지
ports:
- containerPort: 8080
=> Yaml 파일을 API 서버에 게시하면, label selector app=test 1와 일치하는 pod 인스턴스가 3개 유지하도록 하는 test1이라는 이름의 새로운 RC를 생성
Replicaset(RS) 레플리카셋
1. 레플리카셋은 파드 집합의 실행을 항상 안정적으로 유지하며 명시된 파드 개수에 대한 가용성을 보증하는데 사용된다.
2. 레플리카셋을 정의하는 필드는 획득 가능한 파드를 식별하는 방법이 명시된 셀렉터가 나온다.
3. 유지해야 하는 파드 개수를 명시하는 레플리카의 개수
4. 레플리카 수 유지를 위해 생성하는 신규 파드에 대한 데이터를 명시하는 파드 템플릿으로 레플리카셋이 새로운 파드를 생성한다.
5. 레플리카셋은 셀렉터를 이용해서 필요한 새 파드를 식별한다. 레플리카셋의 셀렉터와 일치한다면 레플리카셋이 즉각 파드를 가지게 될 것이다.
6. 레플리카셋은 지정된 수의 파드 레플리카가 항상 실행되도록 보장한다. 그러나 디플로이먼트는 레플리카셋을 관리하고 다른 유용한 기능과 함께 파드에 대한 선언적 업데이트를 제공하는 상위 개념이다. 디플로이먼트를 사용하는 것을 권장한다.
Replication controller(RC) 와 replicaset(RS) 비교
1. 레플리케이션 컨트롤러와 레플리카 셋의 동작 원리는 비슷
2. 레플리케이션 컨트롤러는 균등-기반의 select 요건만을 지원하고, 레플리카셋은 집합-기반의 풍부한 표현식을 사용하는 pod select를 갖는다.
3. 레플리케이션 컨트롤러는 레플리카셋으로 완전 대체 됨
4. RC의 label selector는 특정 label이 있는 pod만을 매칭한다.
RS의 selector는 특정 label이 없는 pod나 label의 값과 상관없이 특정 label key를 갖는 pod를 매칭할 수 있다.
예) RS는 하나의 Replicaset에서 두 pod 세트를 모두 매칭시켜 하나의 그룹으로 취급 할 수 있다. (and)가능
예) RC는 label이 env=A 인 pod와 label이 env=B인 pod를 동시에 매칭할 수 없다. 둘 중에 하나만 매칭할 수 있다. (or)만 가능 즉 AND연산을 할 수 없다.
RS는 AND연산이 가능
예) RC는 값에 상관없이 label key의 존재만으로 pod를 매칭할 수 없다. 정확히 env : A식으로 지정해야 한다.
예) RS는 label의 key존재만으로 pod를 매칭할 수 있다. 즉 env키 만으로 모든 pod를 매칭할 수 있다 env로 지정해도 가능하다. (env=*로 볼 수 있다.)
- 실습
레플리카셋 (RS) 만들기
[root@master1 base]# cat test-rs.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: test1
spec:
replicas: 3
selector:
matchLabels:
app: test1
template:
metadata:
labels:
app: test1
spec:
containers:
- name: test1
image: hewon16/image1:1
ports:
- containerPort: 8080
서비스 컨트롤러
- 명령어 : kubectl get service
1. 네트워크와 관련하여 파드를 외부 네트웍과 연결해주거나 여러 개의 파드를 내부 로드 밸런서를 사용할 수 있도록 하는 역할
2. 로드밸런서 서비스, 노드포트 서비스, 클러스터 서비스등의 서비스가 생성되거나 삭제될 때 해당 서비스를 요청하거나 해제하는 역할을 한다.
엔드포인트 컨트롤러
- 명령어: kubectl get endpoints
1. 엔드포인트 컨트롤러는 서비스에서 정의한 파드의 셀렉터와 일치하는 경우 파드의 ip와 포트로 엔드포인트 리스트를 생성, 갱신한다.
2. 서비스와 파드의 추가, 갱신, 삭제 등을 감시하다 변경이 감지되면 서비스의 파드 셀렉터와 일치하는 파드를 선택해 ip와 포트를 엔드포인트 리소스에 추가한다.
3. 단독 오브젝트인 엔드포인트 컨트롤러는 직접 생성하고 서비스가 삭제되면 해당 엔드포인트 오브젝트를 삭제한다.
네임스페이스 컨트롤러
1. 리소스 이름은 네임스페이스 안에서만 고유하면 된다. 즉 서로 다른 네임스페이스는 동일한 이름의 리소스를 가질 수 있다.
2. 노드 리소스는 네임스페이스를 사용하지 않는 클러스터의 광역적 리소스이다.
3. 리소스에 네임스페이스를 지정하지 않으면 default namespace로 자동 지정
4. 네임스페이스 리소스가 삭제될 경우 여기에 속한 모든 리소스도 함께 삭제된다.
5. 클러스터를 논리적으로 구분하여 관리 할 수 있다. 여러 개의 네임스페이스를 사용하여 더 세부적인 설정으로 유연하고 확장성 있게 리소스를 관리할 수 있다.
컨트롤러 매니저
1. 많은 컨트롤러가 내장되어 컨트롤러 집합을 이루고 이 집합이 하나의 kube-controller-manager 에서 실행 중이다.
(컨트롤러들은 서로의 존재를 모른다.)
2. API 서버로 배포한 리소스의 정의된 상태로 활성 구성하기 위해 각 사항에 맞는 컨트롤러들이 수행된다.
3. 컨트롤러 매니저는 리소스를 배포할 때 실제 작업을 관리하는 구성 요소이다

컨트롤러 매니저의 동작 정리
1. API서버에서 리소스(디플로이먼트, 레플리카셋, 서비스 등)가 수정되는 것을 감시하다 시스템을 원하는 상태로 유지 관리 되도록 컨트롤러 매니저가 동작한다.
2. 컨트롤러는 리소스를 원하는 상태로 조정하고 리소스의 새로운 상태를 기록하기 위해 조정 loop을 실행한다. (예 : 레플리카셋의 감시와 레플리카수 유지를 위한 조정 loop 실행)
3. 각 컨트롤러는 서로 독립적이며 API서버에 연결해 각 컨트롤러의 리소스에 변경사항이 발생하는지 통보하고 요청한다.
예시)
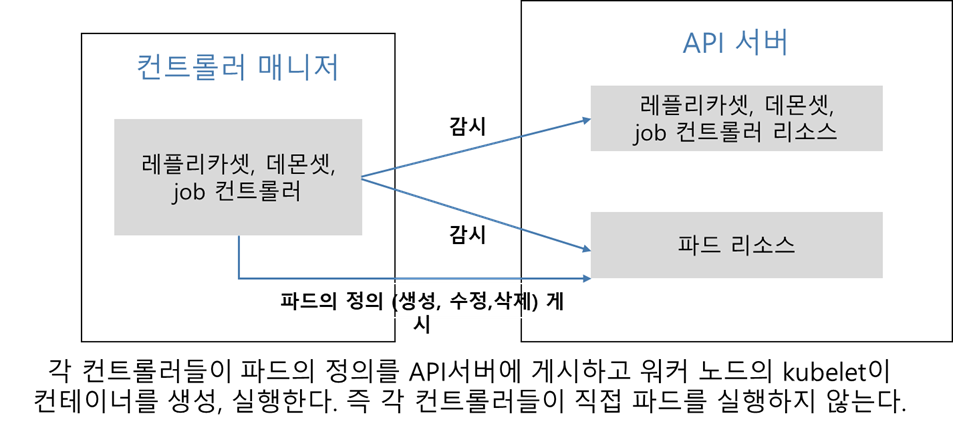
워커노드 구성요소
1) kubelet
모든 워커노드에서 실행되는 에이전트로서 노드에 할당된 파드의 생성, 확인 작업을 수행한다.
PodSpecs 설정에 맞게 컨테이너를 실행하고 상태 등을 체크한다.
2) kube-proxy
가상 네트웍 동작을 설정 및 관리하고 호스트의 네트웍 규칙을 관리하며 연결을 포워딩한다.
서비스와 관련된 연결은 kube-proxy에 의해 처리된다.
3) Container Runtime
컨테이너 런타임은 실제로 컨테이너를 실행시키는 역할 런타임으로는 도커(Docner), runc 같은 런타임도 지원
Kubelet 의미
1. 각 노드에서 실행되는 기본 노드 에이전트
2. PodSpec 으로 작동하고 해당 PodSpec에 정의된 컨테이너가 실행 중인지 정상인지 확인한다.
3. kubelet은 실행 중인 노드를 노드 컨트롤러의 관리하에 노드 리소스로 만들어서 API서버에 등록한다. 즉 노드의 kubelet으로 컨트롤 플레인에 자체 등록한다.
4. API서버를 계속 모니터링 하다가 해당 노드에 파드가 스케줄링 되면, 파드의 컨테이너를 실행한다.
5. 컨테이너를 계속 모니터링하면서 상태, 이벤트, 리소스 사용량을 API 서버에 보고한다.
6. API서버에서 파드가 삭제되면 컨테이너를 정지하고 파드가 종료됨을 통보한다.
- 명령어: kbubectl get nod
- 명령어: kubectl describe node node1
- 워커 노드의 상세정보 요약
- 정보에는 노드가 사용 가능한 리소스를 나타낸다. 리소스에는 CPU, 메모리, 스케줄가능한 최대 파드 개수를 볼 수 있다.
- 커널 버전, 쿠버네티스 버전(kubelet과 kube-proxy 버전), Docker 버전, OS 이름과 같은 노드에 대한 정보를 보여준다. 이 정보는 Kubelet에 의해 정보가 수집된다.
클러스터의 네트워크 이해
1. 클러스터의 네트웍 사용은 컨테이너 네트워크 인터페이스(CNI)에 의해 제공
2. Pause 컨테이너 = 파드 인프라스트럭처 컨테이너
- 하나의 파드내에서 실행중인 여러 컨테이너가 동일한 네트워크와 리눅스 네임스페이스를 공유하는 방법으로 사용한다.
- 리눅스 네임스페이스를 모두 저장하고 있는게 목적인 컨테이너다.
- 사용자 정의 컨테이너들이 파드 인프라구조체인 이 컨테이너의 네임스페이스를 사용한다.
하나의 파드에 여러 개의 컨테이너가 실행 중일 때 사용하는 네트워크 구조
- 같은 파드에 있는 컨테이너들은 동일 ip를 가진다.
- pause컨테이너가 인프라의 역할을 하므로 pause컨테이너가 제공하는 가상의 랜(vethXX)을 공유해서 사용하게 된다.
- pause컨테이너의 해당 네트워크 네임스페이스를 사용한다. 즉, 파드의 네트워크 인터페이스는 인프라 컨테이너인 pause에서 설정한다.
- 일반 단일 파드 내부의 여러 컨테이너간의 통신

- 여러개의 노드와 파드 네트워크 구조

결론 : 파드 네트워크 인터페이스 = 컨테이너 네트워크 인터페이스(CNI) 이다.
네트워크 연결을 위한 서비스

1. 서비스는 파드에 접근할 수 있는 네트워크 서비스로 노출하는 추상적 개념이다.
2. 같은 서비스를 제공 중인 모든 파드에 지속적인 단일 연결지점을 제공하는 리소스
3. 서비스가 제공하는 IP주소와 포트는 고정된다.
클러스터 서비스 만들기
1.yaml 파일 만들기
[root@master1 base]# cat test-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: test-svc
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: test1
2.yaml파일 적용하기 (서비스 만들기)
[root@master1 base]# kubectl apply -f test-svc.yaml
service/test-svc created
3. pod 배포하기
[root@master1 base]# cat test-dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test1
spec:
replicas: 3
selector:
matchLabels:
app: test1
template:
metadata:
name: test1
labels:
app: test1
spec:
containers:
- image: hewon16/image1:1
name: test1
[root@master1 base]# kubectl apply -f test-dep.yaml
deployment.apps/test1 created
4. 배포된 서비스 / pod ip 확인하기
[root@master1 base]# kubectl get all -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/test1-7dd6b645cb-7g99p 1/1 Running 0 2m31s 172.16.180.51 master2 <none>
pod/test1-7dd6b645cb-8rjst 1/1 Running 0 2m31s 172.16.166.141 node1 <none>
pod/test1-7dd6b645cb-zqlrn 1/1 Running 0 2m31s 172.16.136.26 master3 <none>
=> 파드의 ip확인
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3h44m <none>
service/test-svc ClusterIP 10.108.50.147 <none> 80/TCP 10m app=test1
=> 클러스터 서비스 ip확인
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/test1 3/3 3 3 2m32s test1 hewon16/image1:1 app=test1
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/test1-7dd6b645cb 3 3 3 2m31s test1 hewon16/image1:1 app=test1,pod-template-hash=7dd6b645cb
5. 자동으로 생성된 엔드포인트 확인하기
[root@master1 base]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.56.30:6443,192.168.56.31:6443,192.168.56.32:6443 3h49m
test-svc 172.16.136.26:8080, 172.16.166.141:8080, 172.16.180.51:8080 15m
6. 클러스터 내부 클라이언트에서 서비스 ip를 이요한 접속 테스트
- 클러스터 ip는 클러스터 내의 클라이언트 만 사용 가능하다.
- 만약 본인이 GKE를 사용하는 중이면 워커노드 (인스턴스에 실행중인) 에 접속하여 사용한다.
[root@master1 base]# curl 10.108.50.147
test name: test1-7dd6b645cb-7g99p
[root@master1 base]# curl 10.108.50.147
test name: test1-7dd6b645cb-zqlrn
[root@master1 base]# curl 10.108.50.147
test name: test1-7dd6b645cb-8rjst
이번 포스팅에서 쿠버네티스의 개념과 구성요소들에대해 간단하게 알아보았다.
글을 쓰고 나서도 쿠버네티스가 정확히 무엇인지 어떻게 작동하는지에대해 아직 의문 투성인 것들이 많다.
끊임없이 의심하다 보면 언젠가 확신을 갖는날이 올거라고 생각한다!!
다음 포스팅에서는 애플리케이션 배포와 관련있는 디플로이먼트에 대해 알아보겠다.