먼저 JSON과 YAML에 대해 알아보고 시작해보자
- JSON 이란?
1. JSON이란 JavaScript Object Notation의 약자로 쉽게 말해 자바스크립트의 객체 표기법이다.
2. XML을 대체하여 많이 사용된다. 그 이유는 사람과 기계 모두 이해하기 쉬운 표현식이며 용량도 작은편이다.
3. JSON은 단지 데이터를 표현하는 방법일뿐 언어 또는 프로그래밍 문법이 아니다.
- YAML 이란?
1. YAML은 XML, C, 파이썬, 펄, RFC2822에서 정의된 e-mail 양식에서 개념을 얻어 만들어진 '사람이 쉽게 읽을 수 있는' 데이터 직렬화 양식이다.
2. 즉 YAML은 모든 데이터를 리시트, 해쉬, 스칼라 데이터의 조합으로 적절히 표현할 수 있다.
- 기상청 홈페이지에서 RSS데이터 갖고오기
- https://www.weather.go.kr/w/pop/rss-guide.do
RSS 서비스 안내
RSS(Really Simple Syndication, Rich Site Summary)란 블로그처럼 컨텐츠 업데이트가 자주 일어나는 웹사이트에서, 업데이트된 정보를 쉽게 구독자들에게 제공하기 위해 XML을 기초로 만들어진 데이터 형식입
www.weather.go.kr
위 사이트에 들어가서 [중기예보]의 [전국]에 해당하는 RSS데이터를 갖고오자
전국 RSS를 누르면 아래와 같이 나오고 해당 URL을 새탭에서 실행하면 XML형식으로 된 RSS데이터가 나온다.
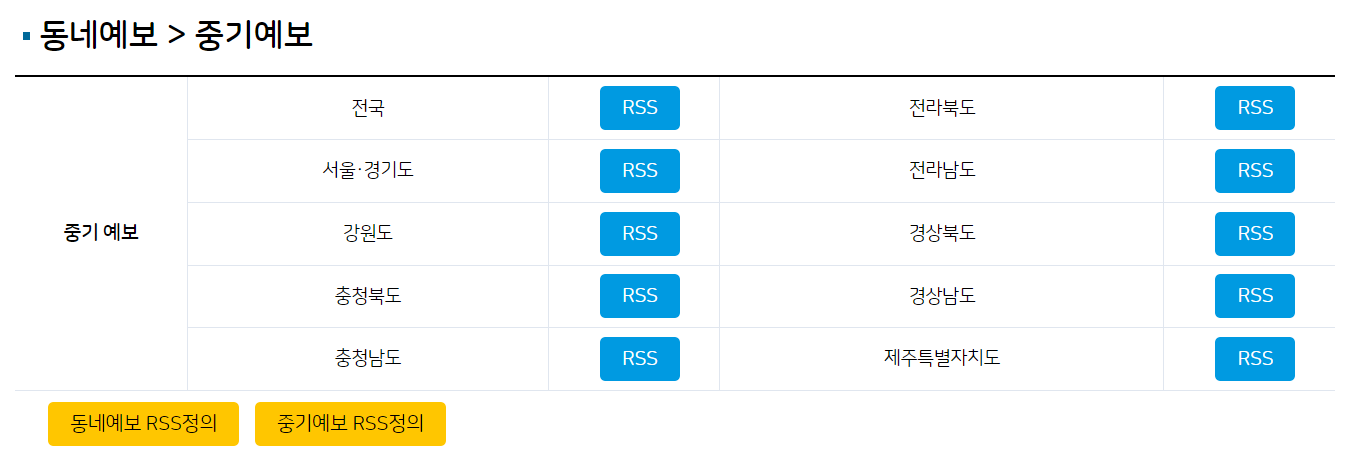

해당 URL을 활용하여 기상청 날씨 데이터를 JSON을 파일로 저장해보자.
1. 먼저 필요한 모듈을 불러온 다음 parsing 해준 후 확인한다.
import requests
#python용 http라이브러리인 requests 모듈을 사용한다.
from bs4 import BeautifulSoup
#parsing을 위해 BeautifulSoup을 사용한다.
url = 'https://www.kma.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=108'
res = requests.get(url) #url을 res로 받는다.
print(res) #200~400 이면 정상으로 rss파일의 데이터를 파싱하거나 특정 tag만 find or select해서 가져온다.
if res.ok:
soup = BeautifulSoup(res.text, 'html.parser')
#url을 res로 받아준거에서 text만 따서 html로 파싱해준다.
#bBeautifulSoup으로 분석하는과정
location_tags = soup.find_all('location', attrs={'wl_ver':3})
#html에서 location wl_ver=3에 해당하는 정보 모두 출력
#attrs속성 사용 soup.find_all('wl_ver':3) ->wl_ver = "3"에 해당하는 태그의 모든 속성을 dict타입으로 반환
#attrs는 해당 엘레먼트에서 속성 추출하는방법
print(location_tags) #원하는 데이터가 find_all() 되었는지 확인한다.
print(type(location_tags)) # type을 확인한다.
print(len(location_tags)) #location의 수를 파악한다.
#type으로 확인가능한 class 'bs4.element.ResultSet'란 list처럼 활용가능 하다는 말이다.
2. 제대로 파싱이 되었다면 내가 원하는 <tag>를 선택하여 정리해보자.
나는 <location>,<city>별로 구분하고 이에 해당하는 <data>의 <mode>,<tmef>,<wf>,<tmn>,<tmx>별로 data를 정리한다.
location_list = []
for location_tag in location_tags:
location_dict = {}
location_dict['province'] = location_tag.find('province').text
location_dict['city'] = location_tag.find('city').text
#해당 url속 'province' 와 'city'를 찾는다. 잘 찾았는지 확인해준다.
#print((location_dict['province']))
#print((location_dict['city']))
#이제 위의 province와 city별로 가진 날씨 데이터를 가져오자
data_tags = location_tag.find_all('data')
#맨 처음 만든 location_tag에서 <data> 부분을 가져온다.
#print(data_tags) #잘 가져오는지 확인해보자.
data_list = []
for data_tag in data_tags:
data_dict ={}
data_dict['mode'] = data_tag.find('mode').text
data_dict['tmef'] = data_tag.find('tmef').text
data_dict['wf'] = data_tag.find('wf').text
data_dict['tmn'] = data_tag.find('tmn').text
data_dict['tmx'] = data_tag.find('tmx').text
data_list.append(data_dict)
#data_list 리스트에 for문을 통해 찾은 data파일들을 더해 data_list를 만든다.
#'NoneType' object has no attribute 'text'
#'tmEf'로 했을 때 나온 코드 시험삼아 data_list를 프린트해보니 출력된값이 하나도없다.... 왜?
# tmEf를 에서 대문자 E를 소문자 e로 바꾸어서 tmef로 입력하니까 문제가 해결됐다...
#print(data_list)
location_dict['datas'] = data_list
#location_dict에 'datas'를 설정해주고 이에 data_list를 넣어 완성
location_list.append(location_dict)
#최종적으로 location_list라는 리스트에 location_dict를 더해줘서 완성
#location list를 출력해보자
print(len(location_list)) # 41개의 'datas': 묶음이 나온다.
print(location_list)
3. location_list에 리스트가 형성되었다.
import json
#json file 저장
with open('weather.json','w') as file:
json.dump(location_list, file)
5. 저장한 json content를 읽어보자.
with open('weather.json','r',encoding='utf-8') as file:
content = file.read()
json_content = json.loads(content)
print(json_content)*

6. 생성된 json 파일을 viewer 로 살펴보자.

7. JSON to YAML
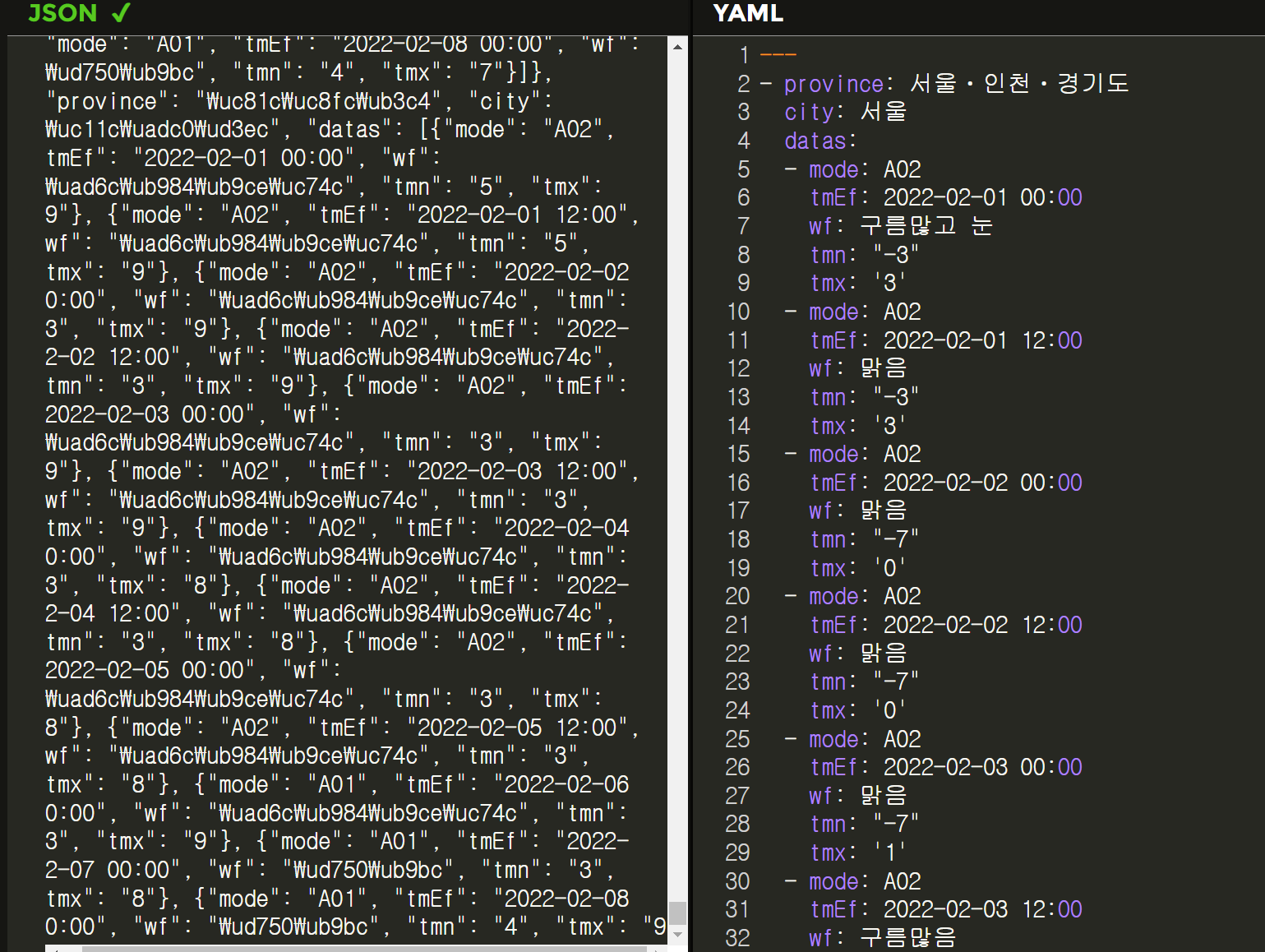



댓글