반응형
[1]. 상관계수 (crrelation)
* 인구수와 면적간에 관련성이 있는지 살펴보기 위해서 상관계수를 구하기
* 상관계수 값음 -1 ~ 1 사이의 값으로 , -1에 가까우면 음에 비례, 1에 가까우면 양의 비례(관련성이높다), 0에 가까울수록 상관x
* 음수는 반비례, 양수는 비례
* corr()함수사용
- corr() 함수 사용
data['면적'].corr(data['인구수'])
-0.3460351605045771
- 서울특별시의 면적과 인구수의 상관계수 구하기
seoul_df = data.loc[data['광역시도'] == '서울특별시']
seoul_df['면적'].corr(seoul_df['인구수'])
0.664426818890978
[2]. Group By 기능
* 광역시도별 인구수의 합계
* ~별에 해당하는 컬럼명이나 컬럼값을 groupby() 함수의 인자로 전달한다.
* Series 객체의 groupby() 함수는 컬럼의 값을 인자로 전달한다.
* DataFrame 객체의 groupby() 함수는 컬럼명을 인자로 전달한다.
- 광역시도별 인구수의 합계
- seriesGroupBy object , series 객체 사용
data['인구수'].groupby(data['광역시도']).sum().sort_values(ascending=False)
- dataframe 사용 편 : dataframe 객체 사용 - 광역시도별 인구수의 합계
data.groupby('광역시도').sum()
- dataframe에서 객체사용
- data를 광역시도로 그룹화하고 인구수 칼럼명을 줘서 시리즈로 나열
data.groupby('광역시도')['인구수'].sum()
print(type(data.groupby('광역시도')['인구수'].sum()))
<class 'pandas.core.series.Series'>
- 액셀파일 만들기
group1 = data.groupby(['광역시도','행정구역'])['인구수'].sum()
group1.to_excel('광역시도별행정구역별인구수의합계.xlsx')

- 액셀 수치 데이터 콤마 찍기
# Create a Pandas Excel writer using XlsxWriter as the engine.
#새로운 변수 = pd.ExcelWriter('새로운 파일 명.xlsx', engine='xlsxwriter') #쓰기모드로 열어준다
writer = pd.ExcelWriter('광역시도별인구수의합계(최종).xlsx', engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object.
#group1 = data.groupby~
#데이터프레임.to_excel(writer, sheet_name='인구수')
group1.to_excel(writer, sheet_name='인구수')
# Get the xlsxwriter workbook and worksheet objects.
workbook = writer.book
worksheet = writer.sheets['인구수합계']
# Set a currency number format for a column.
num_format = workbook.add_format({'num_format': '#,###'})
worksheet.set_column('C:C', None, num_format)
# Close the Pandas Excel writer and output the Excel file.
writer.save()

- 광역도시별 인구수의 max, mean, std집계 함수를 한꺼번에 조회하기
- agg() 사용
group_agg_df = data.groupby('광역시도')['인구수'].agg(['max','mean','std']).fillna(0).sort_values(by='max',ascending=False)
#fillna(): NaN값을 처리가능 EX)fillna(0)으로하면 NaN값 0으로 표시
#.sort_values(by='기준', ascending = True (오름차순), False(내림차순)
group_agg_df.style.format('{0:0.2f}')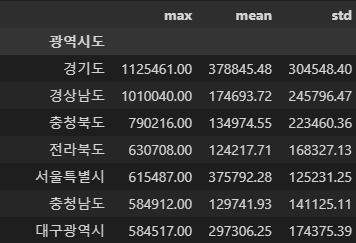
- inplace속성의 default = False
- 변경된 결과를 화면에 출력만 하고 원본 DataFrame을 변경하지 않음
- inplace = True일 때는 변경된 결과를 화면에 출력하지 않고 원본 dataframe을 수정한다
group_agg_df.reset_index(level='광역시도', inplace=False)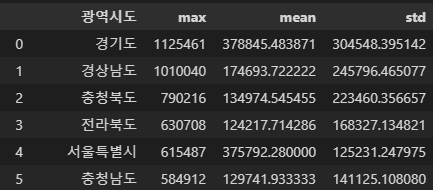
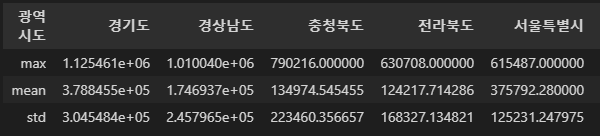
- 행과 열을 바꾸고 싶다면 T속성 이용
-
group_agg_df.T
[5]. 시각화
### 시각화
* plot이 출력되려면 show()함수를 호출을 해야 하지만, jupyter에서는 show()함수를 호출하지 않아도 된다.
* %matplotlib inline 설정을 해줘야한다.
* plot에 대한 설정은 matplotlib의 함수들을 사용하고 seaborn의 함수들을 사용한다.
- 필요한 matplotlib 모듈 import 해오기 + seaborn
%matplotlib inlineimport matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
- 폰트 설정하기
# 폰트이름과 폰트 파일 정보 출력: list comprehension
[(font.name, font.fname) for font in fm.fontManager.ttflist if 'Ma' in font.name]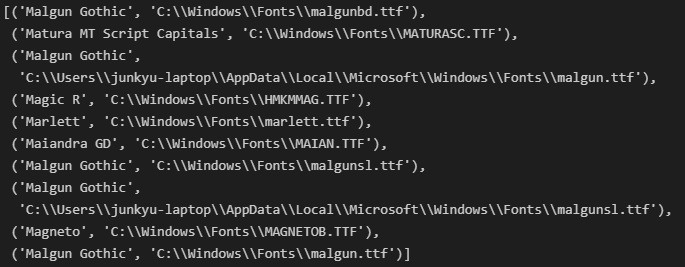
'ma'을 갖고 있는 폰트 정보들 출력
#한글폰트 설정
font_path = 'C:\\Windows\\Fonts\\malgun.ttf'
# font의 파일정보로 font name을 알아내기
font_prop = fm.FontProperties(fname=font_path).get_name()
print(font_prop)
# matplotlib의 rc(run command) 함수를 사용해서 폰트이름 설정
matplotlib.rc('font', family=font_prop)
Malgun Gothic- 용어 정리
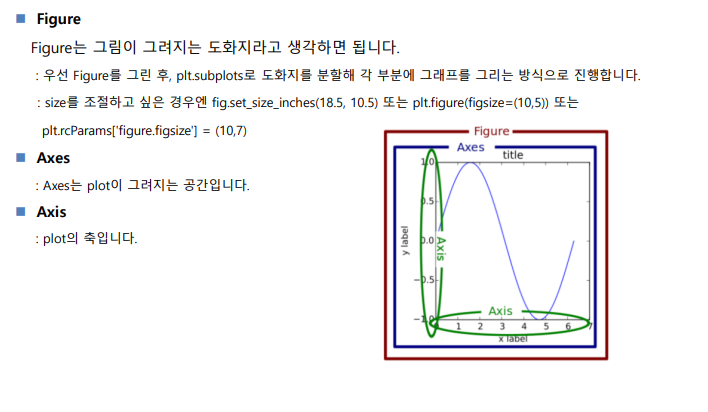
## Figure, Axes
* Figure는 Plot이 그려지는 도화지
* Axes는 Plot의 그려지는 공간
* Figure에 Axes를 여러개 생성해서 Figure를 분할해서 Plot을 그릴 수 있음
* seaborn()에서 제공하는 막대그래프를 그릴 수 있는 barplot() 함수 사용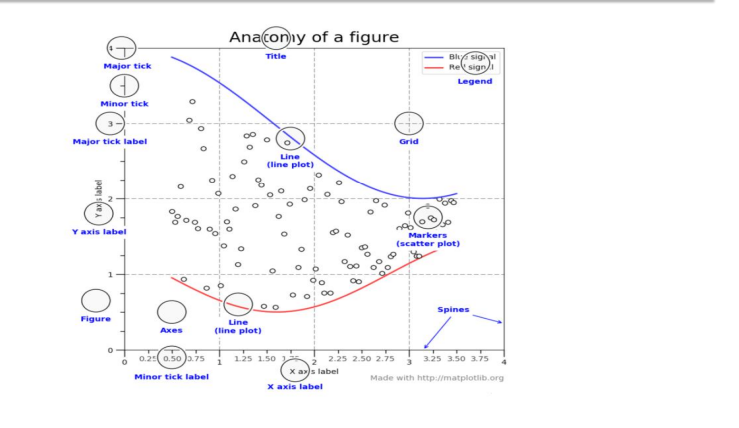
- 그래프 만들어보기
- 도화지에 Plot을 통해 도화지 일부분을 가져오고 size을 설정한다.
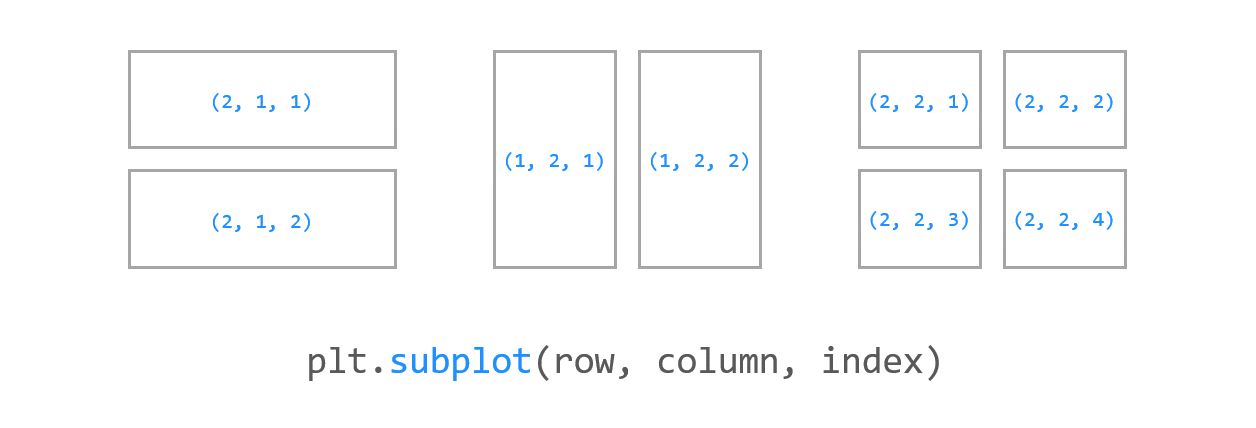
figure,(axes1,axes2) = plt.subplots(nrows=2, ncols=1)
figure.set_size_inches(18,12)
print(figure)
print(axes1)
print(axes2)-plt.subplots의 사용법을 잠시 살펴보고 가자 # 우리는 nrows=2, ncols=1로 주어서 맨 좌측과 같은 figure형성

seaborn을 사용하여 barplot을 그려보자
예시). sns.barplot(x축='칼럼명', y축='칼럼명', data=데이터_df.sort_values(by='인구수', ascending=False), ax=axes1)
*데이터_df를 인구수 칼럼을 기준으로 내림차순으로 정렬하여 그래프가 예쁘게 나오도록 함.
figure,(axes1,axes2) = plt.subplots(nrows=2, ncols=1)
figure.set_size_inches(18,12)
print(figure)
print(axes1)
print(axes2)
sns.barplot(x='행정구역', y='인구수', data=seoul_df.sort_values(by='인구수', ascending=False), ax=axes1)
sns.barplot(x='행정구역', y='면적', data=seoul_df.sort_values(by='면적', ascending=False), ax=axes2)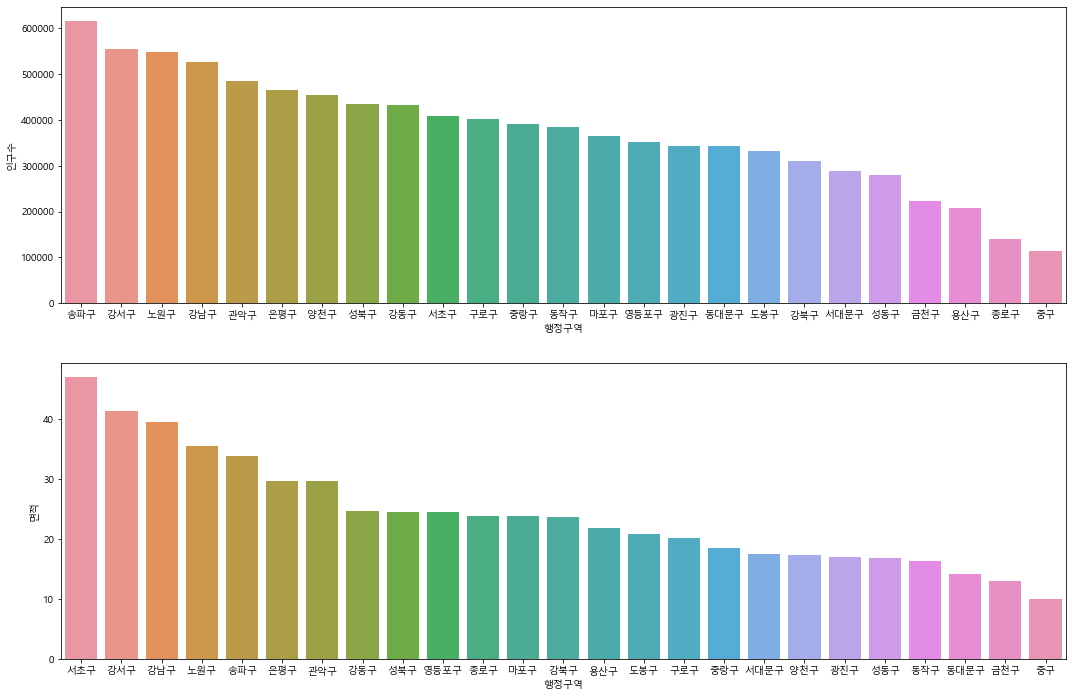
- 원하는 광역시도의 행정구역별 인구수, 면적을 barplot으로 나타내는 함수 만들기
def print_barplot(sido_name):
sido_df = data.loc[data['광역시도'] == sido_name]
figure,(axes1,axes2) = plt.subplots(nrows=2, ncols=1)
figure.set_size_inches(18,12)
a = sns.barplot(x='행정구역', y='인구수', data=sido_df.sort_values(by='인구수', ascending=False), ax=axes1)
a.set_title(f'{sido_name} 행정구역별 인구수') #타이틀도 달아줄수있다.
b = sns.barplot(x='행정구역', y='면적', data=sido_df.sort_values(by='면적', ascending=False), ax=axes2)
b.set_title(f'{sido_name} 행정구역별 면적')
print_barplot('경기도')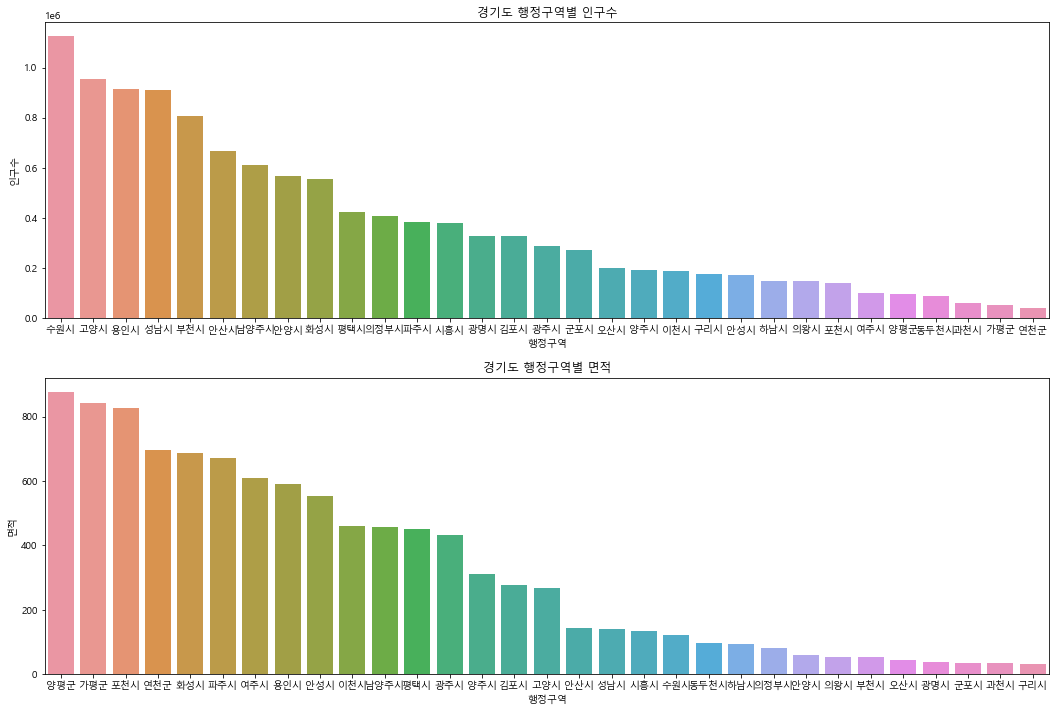
- 응용
1. 서울특별시의 행정구역별 인구수 barplot에 해당 인구수 나타내기
figure, ax1 = plt.subplots(nrows=1, ncols=1)
figure.set_size_inches(18,12)
sns.barplot(data=seoul_df, x="행정구역", y="인구수", ax=ax1)
ax1.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax1.set(ylabel='인구수')
for item in ax1.get_xticklabels():
item.set_rotation(90)
for i, v in enumerate(seoul_df["인구수"].iteritems()):
ax1.text(i ,v[1], "{:,}".format(v[1]), color='m', va ='bottom', rotation=45)
plt.tight_layout()
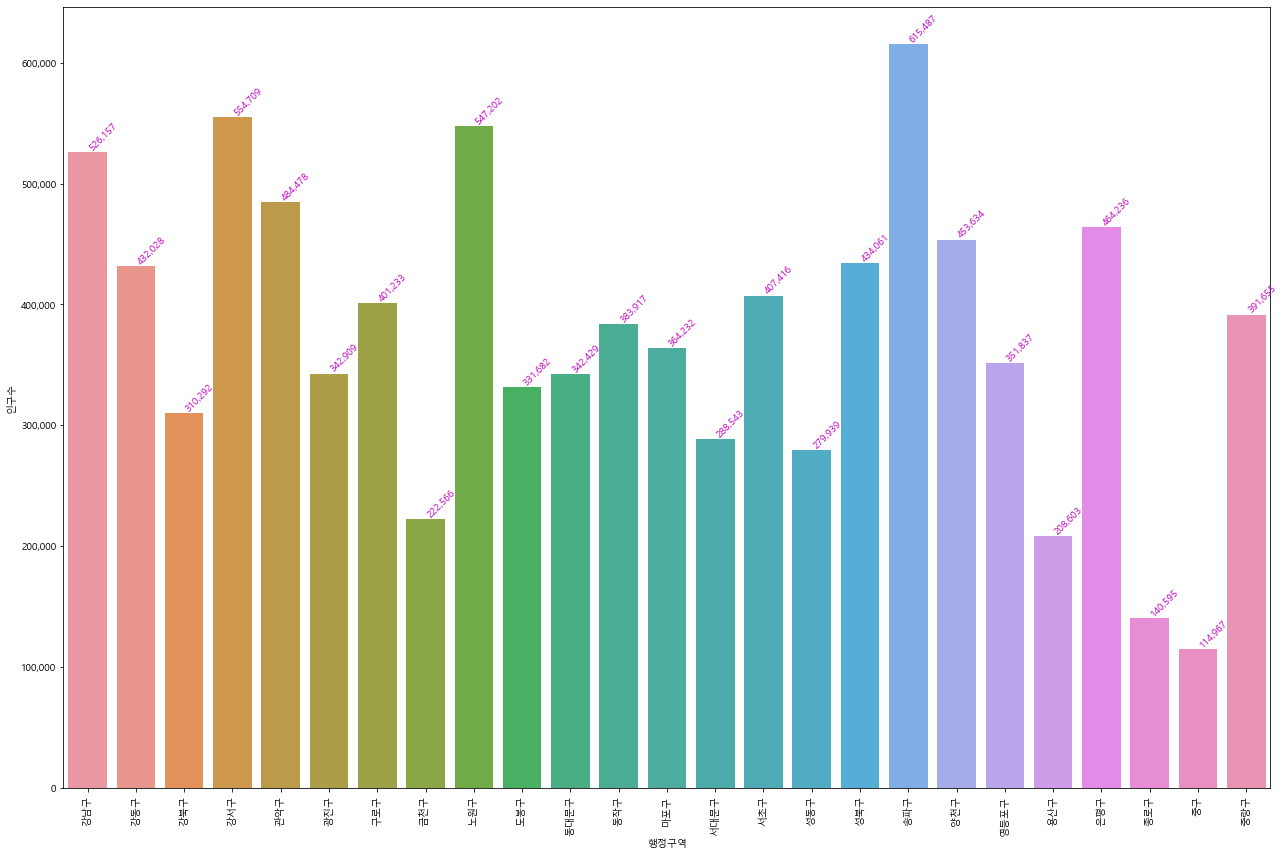
2. 강원도의 행정구역 별 인구수
figure, axes1 = plt.subplots(nrows=1, ncols=1)
figure.set_size_inches(18,12)
sns.barplot(x='행정구역', y='인구수', data=kangwon_df.sort_values(by='인구수', ascending=False), ax=axes1)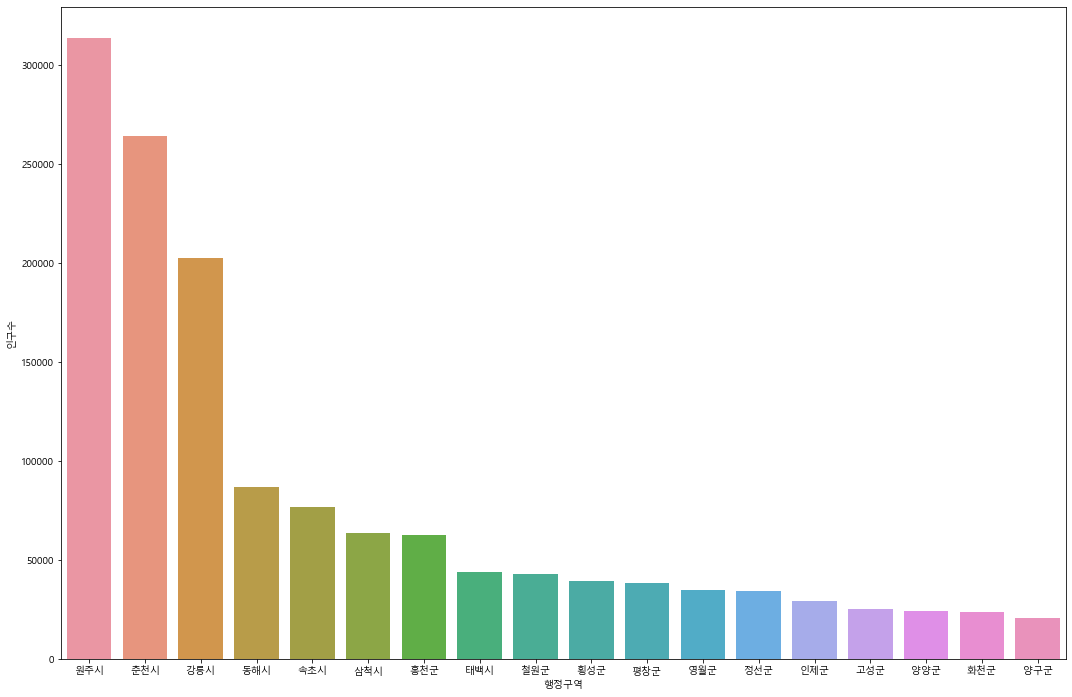
반응형



댓글