목차
프로젝트 회고록의 2번째 포스팅이다.
이전 포스팅에서는 프로젝트의 전체적인 설정을 구성하고 django로 backend부분을 설정하면서
어려웠던 부분을 중심으로 포스팅을 구성했다.
이번 포스팅에서는 ReactJS를 통해 웹페이지를 구성할때
어려움을 겪었던 부분과 트러블 슈팅을 하면서 얻은 경험을 위주로 포스팅할 것같다.
또한 전체 서비스를 AWS EKS를 사용하여 배포하는 법에 대해서도 정리해보겠다.
(이 과정에 웃지못할 해프닝이 일어났었다 ... 학원에서 준 AWS 계정을 통해 배포한줄 알았는데 알고보니까 개인 프리티어를 사용하여 배포를 진행했었던것 ... 나름 배포한다고 3~4일 켜놓았는데 예상보다 사용금액이 너무 많이 나와서 당황했었다 !! 하지만 침착하게 AWS에 연락한 결과..... AWS 측에서 무료 크레딧을 제공해줘서 무사히 넘어갈 수 있었다.)
우선 프로젝트 소스코드 주소 이다 ㅎㅎ
GitHub - codemonkyu/Movie_project: multicampus_cloud_team4
multicampus_cloud_team4. Contribute to codemonkyu/Movie_project development by creating an account on GitHub.
github.com
ReactJS란?
React는 웹 프레임워크로, 자바스크립트 라이브러리의 하나로서 사용자 인터페이스를 만들기 위해 사용된다.
- React는 facebook의 소프트웨어 엔지니어 jordan walke가 만든 자바스크립트 라이브러리이다.
- SPA(Single Page Application)나 모바일 애플리케이션의 개발 시 토대로 사용될 수 있다.
ReactJS은 왜쓰는건데 ??
React는 단방향 데이터 흐름을 가진다.
React의 장점을 쉽게 이해하기 위해서는 React는 단방향 단방향 데이터 흐름(one-way data flow)을 가진다는 것을 알아야 한다. 단방향 데이터 흐름이란 쉽게 말해서 한쪽 흐름으로 데이터를 디자인 한다고 생각하면된다. 예를들어 reactjs에는 컴포넌트가 존재하는데 부모 컴포넌트(상위 컴포넌트)에서 자식 컴포넌트(하위 컴포넌트)로 데이터의 흐름이 형성된다. 하지만 어떠한 이벤트가 발생했을대 자식 컴포넌트의 변화로 부모 컴포넌트의 상태가 변화하는 경우가 있는데, 이를 방지하기 위해 상태를 변경시키는 함수 자체를 자식 컴포넌트에 prop으로 전달하여 해결할 수 있는 것이다.(콜백 함수 사용)
- props = '변하지 않는 값'으로 컴포넌트 바깥에서 데이터를 속성으로 받게 해 준다. 쉽게 말해, 데이터를 전달해주는 보모 컴포넌트이다. 부모 컴포넌트로부터 데이터를 받은 자식 컴포넌트는 전달받은 데이터가 어디서 왔는지 모른다. 즉, prop는 이를 전달해준 최상위 부모 컴포넌트만 변경 가능한 읽기 전용 데이터이다.
- state = '변하는 값' 사용자가 입력한 이벤트에 따라 얼마든지 변경이 가능한 값이다. 예를 들어 페이스북의 게시물에 댓글을 추가 및 삭제할 때 이벤트가 '변경'되므로 이러한 컴포넌트는 state 상태로 두어야 한다. 즉, state는 사용자와 상호작용을 통해 데이터를 동적으로 변경할 때 사용한다. state 컴포넌트가 많을수록 복잡도가 높아지기 때문에 최소화하는 것이 좋다.
React의 구조와 컴포넌트에서 props와 state에 대한 상태에 대한 이해가 끝났으면 React를 사용할 준비가 거의 끝났다고 할 수 있다. 하지만 나는 이해가 잘 되지 않아 Reactjs를 사용한 클론 코딩 관련 강의를 들었는데 많은 도움이 되어서 공유해보겠다.
ReactJS로 영화 웹 서비스 만들기 – 노마드 코더 Nomad Coders
왕초보를 위한 React
nomadcoders.co
만약 강의까지 다 들었다면 이제 리액트를 왜 사용하는지에 대해 어느 정도 감이 올 것이다.
내가 느낀 바로는 리액트의 장점은 아래와 같다.
1. 단순하다 : 컴포넌트를 통해 복잡성을 줄이고 구조를 간단화시킬 수 있다.
2. 배우기 쉽다: JavaScripts와 Html, CSS에 대해서 어느 정도만 알고 있으면 금방 배울 수 있다.
3. 직관적 : 리액트는 직관적이다. 선언형 프로그래밍으로 목적에 집중하여 설명하기 때문에 코드를
단순화할 수 있다.
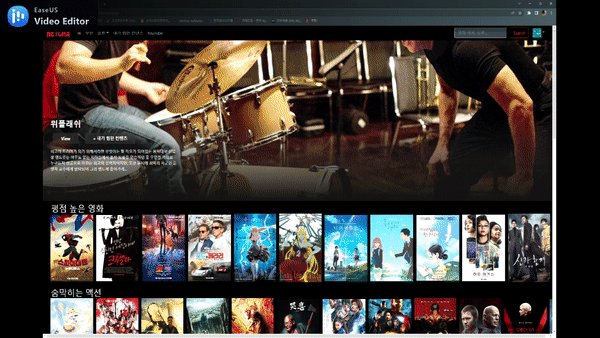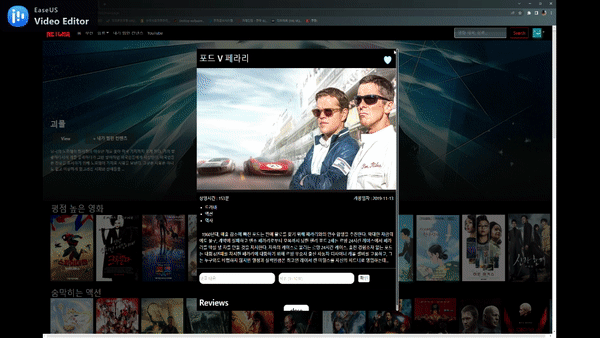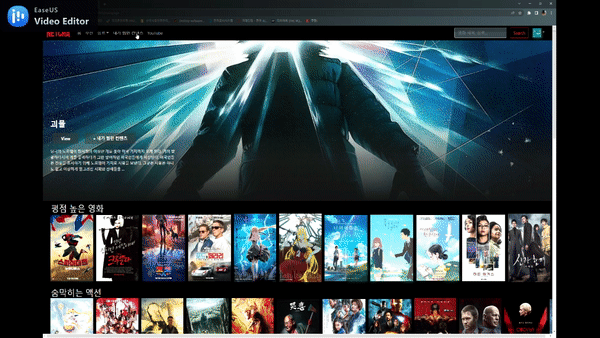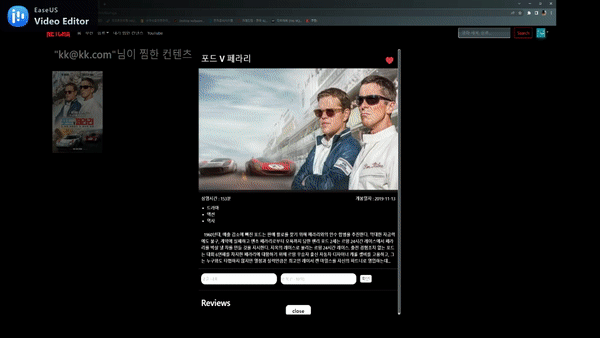
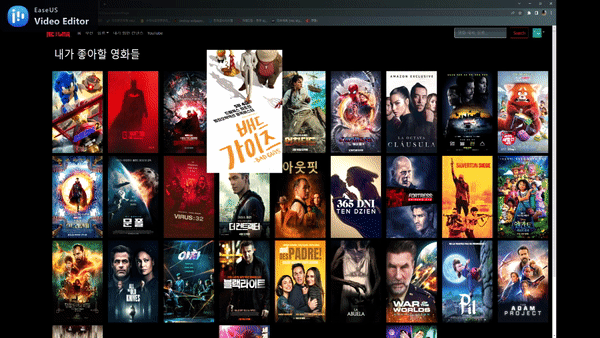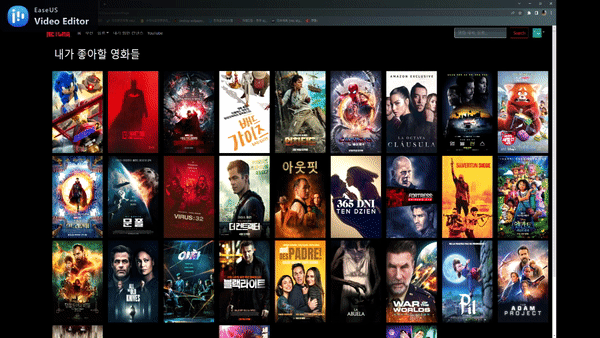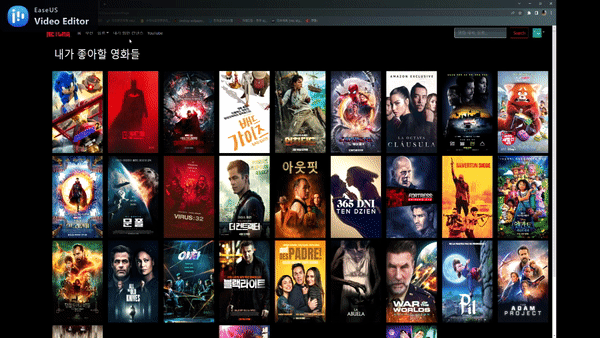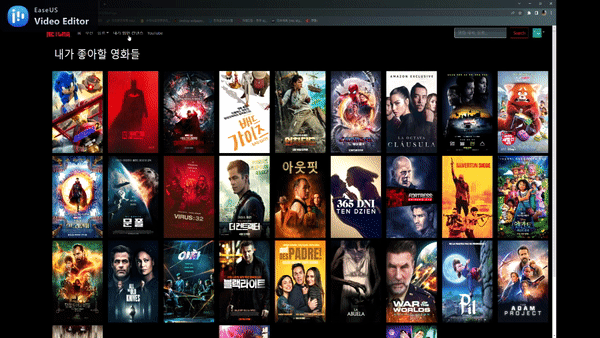
ReactJS를 이용한 웹페이지 만들기
로그인 & 회원가입 페이지

메인 페이지
상세페이지 & 리뷰 생성, 수정, 삭제
검색 기능
Youtube 검색 페이지
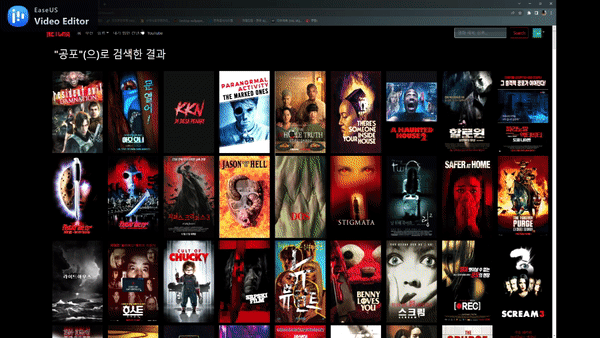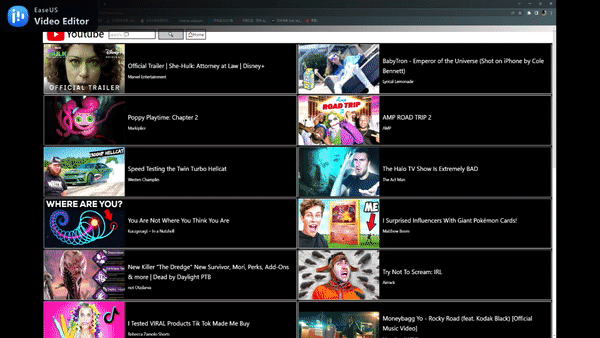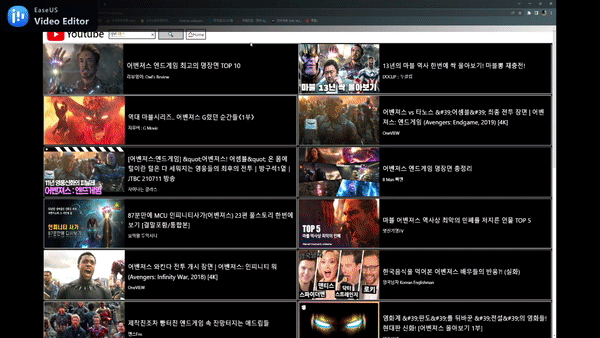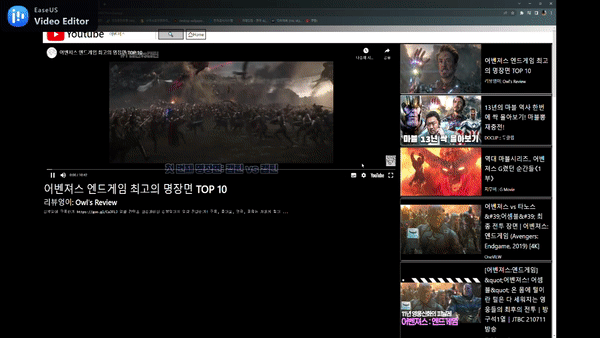
찜하기 기능 및 추천 기능
Docker 사용하여 배포하기
Docker 란 애플리케이션을 신속하게 구축, 테스트 및 배포할 수 있는 소프트웨어 플랫폼이다.
Docker는 애플리케이션을 간편하고 빠르게 테스트하고 배포할 수 있도록 도와주는 플랫폼이다. 도커가 이러한 것들이 가능한 이유는 컨테이너 기반의 가상화 플랫폼을 사용하기 때문이다. 우리가 흔히 알고 있는 화물선의 컨테이너를 떠올려보자 컨테이너는 다양한 물건을 실을 수 있으며 일정한 크기로 규격화되어 있기 때문에 어떤 환경에서든 쉽게 운반되어질 수 있다.
Docker는 컨테이너별로 프로세스를 분리하여 작업공간을 구분한다. 즉, 작업에 필요한 프로세스가 있는 컨테이너만 있으면 어디서든 쉽게 작업환경을 만들 수 있다. 해당 과정은 가상화를 기반으로 이루어지지만 기존의 os 가상화 방법과는 큰 차이가 있다.
기존 os가상화와 docker에서 쓰이는 가상화의 차이점과 docker가 컨테이너 환경을 구성하는 과정은 아래에 정리해놓았다.
[Docker]Docker는 무엇인가?
[이전 글] [가상화와 컨테이너] 가상화와 컨테이너의 차이점 이번 포스팅은 가상화와 컨테이너의 차이점을 다뤄보겠다. 우선 가상화에 대한 개념 혹은 하이퍼바이저(hypervisior)에 대한 개념이 없
codemonkyu.tistory.com
docker의 개념과 실행 순서를 간단하게 설명해보자면
1. docker는 프로세스를 컨테이너화 시켜 가상화 환경에서 실행시켜준다.
2. 컨테이너는 프로세스 실행에 필요한 파일 및 설정 값 등을 포함하고 있다.
3. docker의 컨테이너를 build 하기 위해선
프로세서의 파일 및 설정값(dockerfile)을 우선 이미지화(dockerimage) 시켜줘야 한다.
Dockerfile 만들기
docker 이미지를 생성하기 위해선 우선 dockerfile을 만들어줘야 한다. dockerfile에선 이미지화할 실행 파일 및 설정값을 입력해준다고 생각하면 편하다. dockerfile을 만들 때 주의점은 file을 만드는 디렉터리 위치와 명령어가 실행시키는 파일의 위치가 일치해야 한다.
아래는 이번 프로젝트에서 django로 만든 백엔드 부분에 대한 dockerfile이다.
FROM python:3.8
WORKDIR /usr/src/app
COPY . .
ENV PYTHONIOENCODING=utf-8
ENV ENV_NAME=prod
WORKDIR ./NETCHA
RUN pip install -r requirements.txt
CMD python3 manage.py migrate && \
python3 manage.py runserver 0:8000
EXPOSE 8000각 명령어에 대해 설명해보자면
- FROM: 베이스 이미지이다. django는 python 언어로 구성되었기 때문에 python으로 설정한다.
- WORKDIR: 명령어를 실행항 디렉터리를 설정한다.
- RUN: 도커 이미지가 생성되기 전 전에 수행할 쉘 명령어이다.
- COPY: Docker 클라이언트의 현재 디렉터리에서 파일을 추가한다.
- CMD: 컨테이너가 시작될 때마다 실행할 명령어를 설정한다. Dockerfile에서 한 번만 사용할 수 있다.
- EXPOSE: dockerfile의 빌드로 생성된 이미지에서 노출할 포트를 설정한다.
dockerfile 내용 정리: 베이스 이미지는 python을 사용하며 /usr/src/app 디렉터리에 아래 ENV환경설정을 복사해 넣는다. 그리고 다시 NETCHA(django 프로젝트 폴더명)으로 들어와서 requirements를 통해 필요한 라이브러리를 실행하고 migrate 이후 서버를 시작해준다.
Docker image 만들기 (build)
docker build -t 도커 아이디/이미지 이름 디렉터리 경로/ (dockerfile이 존재하는) 보통은 디렉터리를 일치시키고. 을 붙인다.
docker build -t ljk0509/test1 .
위의 명령어로 도커 이미지를 만들어 컨테이너가 사용할 실행파일과 설정을 저장해준다.
Docker 컨테이너 실행하기 (run)
docker run -it 도커아이디/이미지이름
위의 명령어로 원하는 환경에 도커이미지로 저장된 실행파일과 설정을 컨테이너화 시켜준다.
Kubernetes 사용하여 배포하기
쿠버네티스란 컨테이너화 된 워크로드와 서비스를 관하기위한 오픈소스 플랫폼이다. 쉽게말해, 우리가 docker를 활용해서 컨테이너화된 프로세스들을 조직적으로 쉽게 관리할 수 있는 플랫폼이라고 생각하면 된다. 그럼 왜 쿠버 네티스를 사용할까? 서비스를 컨테이너화 하여 관리하는 목적에 대해 다시 한번 생각해보자, 전 세계적으로 배포되고 있는 서비스가 있다 해당 서비스를 구현하기 위한 프로세서는 크게 구분해도 몇십 가지이며 이를 구성하고 있는 작은 단위의 프로세서들은 몇 백개 될 것이다. 컨테이너화 시킨 몇백 개의 프로세서는 24시간 서비스가 유지되도록 관리되어야 한다. 컨테이너 단위로 서비스를 관리한다면 장애가 일어나고 서비스가 업데이트될 때 매번 장애가 난 컨테이너를 찾고 이를 삭제하고 다시 배포해야 하며 업데이트도 같은 방식으로 번거롭게 진행될 것이다. 만약 이런 과정을 탄력적으로 실행시켜주는 프레임워크가 있다면? 사용하지 않을 이유가 없다. 바로 그것이 쿠버 네티스이다. 즉, 쿠버 네티스는 애플리케이션의 확장과 장애 조치를 처리하고 배포 패턴등을 제공한다!
쿠버네티스는 다음을 제공한다.
- 서비스 디스커버리와 로드 밸런싱 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱 하고 배포하여 배포가 안정적으로 이루어질 수 있다.
- 스토리지 오케스트레이션 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
- 자동화된 롤아웃과 롤백 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
- 자동화된 빈 패킹(bin packing) 컨테이너화된 작업을 실행하는 데 사용할 수 있는 쿠버 네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버 네티스에게 지시한다. 쿠버 네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
- 자동화된 복구(self-healing) 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
- 시크릿과 구성 관리 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트할 수 있다.
위의 쿠버 네티스가 제공하는 서비스를 이해하기 위해서는 쿠버 네티스의 클러스터 구성요소에 대해 어느 정도 이해를 하고 있어야한다. 만약 어느정도 이해가 필요한 사람은 아래 주소를 참고하기 바란다.
[Kubernetes] 쿠버네티스란 ?
쿠버 네티스(kubernetes)란 쿠버네티스는 컨테이너화 된 워크로드와 서비스를 관리하기 위한 오픈소스 플랫폼이다. 컨테이너 오케스트레이션 중 하나로 컨테이너 오케스트레이션은 컨테이너의 배
codemonkyu.tistory.com
AWS EKS cluster 만들기
Kubernetes는 cluster를 통해 '컨트롤 플레인', '컨트롤러', '노드' 등을 구성하는데 이를 통해 컨테이너가 포함된 pod를 효율적으로 관리할 수 있다. 즉 쿠버 네틱스 한 환경을 구성하기 위해서는 cluster를 먼저 구성해야 한다. 나는 가장 기본적인 수준의 클러스터인 모든 컨트롤 플레인 및 워커 노드 서비스가 하나의 머신에서 실행되는 형식으로 만들었다.
#클러스터 생성 명령어 (예시) #aws cli 사용
eksctl create cluster --name 클러스터 이름 --region 리 전명 --with-oidc --ssh-public-key ssh키 이름 --nodes 2 --node-type t3.medium --node-volume-size=20 --managed
배포 관리 (service)
cluster를 만들었다면 이제 object를 관리하는 서비스를 만들어야 한다. object란 pod가 배포되는 단위로 서비스는 가장 작은 배포 단위의 pod를 관리하는 방법이다.
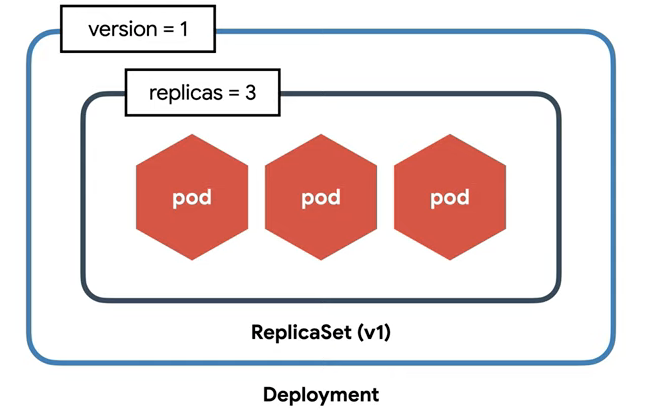
- pod: 가장 작은 배포단위 여러 개의 컨테이너는 하나의 pod에 존재할 수 있음
- Replicaset : 여러개의 pod를 관리할 수 있음. 즉, pod를 생성 및 삭제 등에 관여함 새로운 pod를 생성할 때 template를 참고하며 replicas 수에 맞게 pod 수를 관리한다.
- Deployment : Replicaset의 버전을 관리함. 즉 Replicaset 단위에서 버전을 수정하면 이를 반영하는 단위에서 새로운 pod를 생성하고 삭제하고 유지하는 것이 번거로움
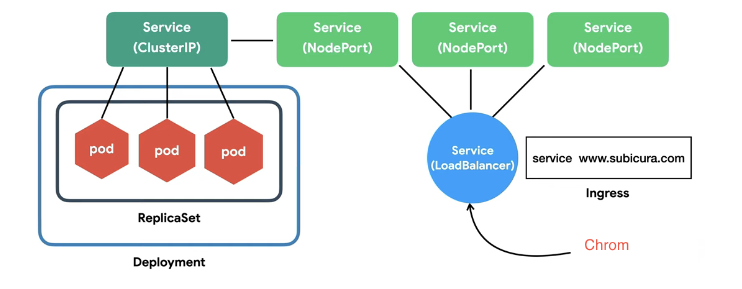
Service — Cluster IP
클러스터 내부에서 사용하는 프락시 Pod은 동적이지만 서비스는 고유 ip를 가지기 때문에 외부에서 어떤 요청을 할 때 서비스의 고유 ip를 통해서 원하는 pod에 요청을 보낼 수 있다. Cluster IP로는 외부 웹브라우저에서 pod으로 전달할 수 없기 때문에 Node를 이용한다.
Service — Node Port
노드에 노출되어 외부에서 접근 가능한 서비스
웹브라우저는 노드 포트를 통해 클러스터 IP에게 요청사항을 전달, pod에 그 요청사항이 도달한다.
Service — Load Balancer
내가 1번 노드와 웹 브라우저를 연결해뒀는데 1번 노드가 삭제되는 경우, 순간적으로 접속이 안되고 수동적으로 2번 노드로 재연결을 시켜야 한다. 이럴 때 자동으로 노드를 연결시켜줄 수 있도록 로드 밸런서를 이용한다.
Ingress
위와 같은 설명은 ip port로 접속을 하는 방법이라면, 도메인 또는 경로 별 라우팅을 통해 접속을 하고자 하면 ingress를 통하면 된다. 모든 도메인에 대해 전부 노드 포트를 만들거나 로드 밸런서를 만들면 자원이 낭비가 되기 때문에 ingress 내부적으로 service를 만들어 접근한다. 이 과정에서 ingress는 자동으로 Service (load balacer)를 생성한다.
나는 django (서버) & react (클라이언트) & rds(데이터베이스) 3개의 서비스를 만들고 delpoy 해야 한다.
1. 먼저 django service를 만들어준다.
apiVersion: v1
kind: Service
metadata:
name: django-svc
spec:
selector:
app: django
ports:
- port: 8000
targetPort: 8000
type: LoadBalancer
2. 이후 만들어놓은 django dockerimage를 이용하여 deploy 명세서를 작성한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: django
spec:
selector:
matchLabels:
app: django
replicas: 1
template:
metadata:
labels:
app: django
spec:
containers:
- name: django
image: ljk0509/project:netcha_v4 #django docker 이미지
ports:
- containerPort: 8000
3. react service & deploy
apiVersion: v1
kind: Service
metadata:
name: react-svc
namespace: default
spec:
selector:
app: react
type: LoadBalancer
ports:
- name: react
protocol: TCP
port: 80
targetPort: 80
--------------------------------------------------------------------------------------------
apiVersion: apps/v1
kind: Deployment
metadata:
name: react
spec:
selector:
matchLabels:
app: react
replicas: 1
template:
metadata:
labels:
app: react
spec:
containers:
- name: react
image: ljk0509/project:react_v2
ports:
- containerPort: 80
4. RDS service
apiVersion: v1
kind: Service
metadata:
name: mysql-svc
spec:
type: ExternalName
externalName: movie-app2.czb1hdtr33mt.ap-northeast-3.rds.amazonaws.com ##RDS 엔드포인트
ports:
- port: 3306
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
간단하게 EKS를 활용하여 내가 만든 서비스를 배포하는 방법을 정리해보았다.
디테일하게 설명하지 못한 부분도 많지만
전체적인 흐름을 알면 디테일한 부분을 쉽게 해결할 수 있다고 생각한다.
전체적인 흐름은 아래와 같다.
1. 서비스의 컨테이너화 (docker image)
↓
2.Kubernetes를 사용하기 위한 cluster 구성
↓
3. 서비스 배포를 위한 명세서 작성 및 실행 배포
사실상 가장 중요한 부분은 서비스의 컨테이너 화이다.
배포를 위한 docker image를 만들기 위해서는 사실 환경변수를 설정하여 배포와 개발환경을 구분해주어야 한다.
react 부분 환경변수 설정에 대한 글이다.
처음에 이 부분이 이해되지 않았지만
결국, env를 통해 환경변수 관련 파일을 만들어주면
배포&개발 시 자체적으로 우선순위를 적용하여 실행시켜준다는 뜻이다.
[react] 실무 개발 환경/배포 환경 설정(.env)
리액트(.env)로 개발 시 개발 환경과 배포 환경에 대한 기본 설정을 해보자. 기본적으로 우리는 Nodejs위에서 개발을 한다. 그리고 package.json 파일에 기본 설정을 하게 된다. 하지만, 개발을 진행하
han-py.tistory.com
또한 나 같은 경우 SPA 방식의 프런트를 구성함으로써 웹서버 엔진을 nginx를 사용했는데 이를 Front 부분 파일에 연결해주는 작업도 진행해야 했다. 아마 spa 방식의 프런트를 구성한 프로젝트는 해당 과정이 필수 일 것이다.
작업은 간단하다 nignx 디렉터리를 front 디렉터리 안에 생성한 뒤 nginx.conf 파일 생성 후 아래와 같이 작성해주면 된다.
nginx.conf 스크립트 작성에 대한 설명은 따로 하지 않겠다!
(검색하면 훌륭한 레퍼런스들이 많이 나온다 ㅎㅎ..)
server {
listen 80;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}완벽하지는 않지만 내가 처음으로 완성한 프로젝트를 정리하는 글을 포스팅해보았다.
프로젝트를 진행하며 불가능할 것 같은 부분을 하나하나 구현해가며 자신감과 실력을 얻을 수 있었다.
진행 과정 속에서 불확실하고 명확하지 않은 지식을 채워가며, 문제를 핸들링하고 해결하는 능력이 많이 늘어난 것 같아서 뿌듯하다.
매 순간, 내 경험과 감정을 모두 기억하고 완전히 내 것으로 만들기는 쉽지 않다.
하지만 작은 것이라도 기록하고 내 것으로 만들기 위해 노력한다면
언젠가는 1%가 모여 100%가 될 수 있다 생각한다. :)

댓글