이번 글에서는 NUMA 가 무엇인지, 리눅스에서 NUMA를 어떻게 관리 할 수 있는지를 알아볼 것이다.
이글을 통해서 최종적으로, 리눅스에서 NUMA의 메모리 할당 정책별 특징을 이해하고 , 워크로드 별 가장 효율적인
정책이 무엇인지 정리하여 Linux 시스템 운영시 메모리 관리 작업 시 도움이 될 수 있을 것이다.
NUMA 란?
NUMA (Non-uniform memory access) 란
그대로 해석하면, "불균형 메모리 접근" 으로 멀티 프로세서 환경에서 적용되는 메모리에 대한 접근 방식이다.
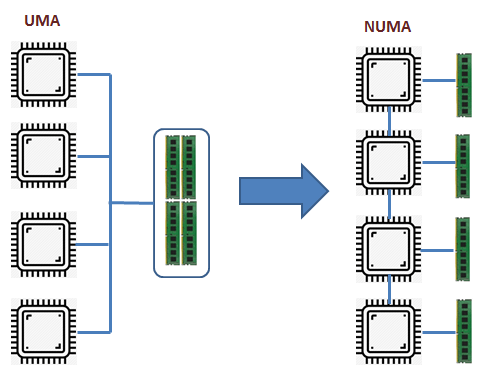
NUMA를 쉽게 이해하기 위해서는 NUMA와 반대 개념에 있는 UMA 아키텍처 를 같이 살펴보면 좋다.
과거에는 프로세서가 균일 메모리 접근(UMA) 시스템 으로 설계되어 모든 프로세서가 동일한 버스(공용 BUS)를 통해 메모리에 엑세스하였다. 하지만 이렇게 단일 BUS를 사용하여 여러 CPU가 메모리에 액세스 하는 경우 BUS 대역폭의 제한된 한계 때문에 병목 현상이 발생하는 문제점이 있다.
UMA와 다르게 NUMA 아키텍처에서는 사용가능한 전체 메모리를 개별 CPU에 분할하여 로컬 메모리로 할당한다. 개별 CPU들은 로컬 메모리에 동시에 액세스 할 수 있으며, (로컬 액세스) 로컬 메모리의 용량이 부족한 경우
다른 CPU에 할당된 로컬 메모리에 접근 할 수 있으나(리모트 액세스) 로컬 액세스에 비해 지연 시간이 늘어나게 된다.
아래의 그림을 보면 UMA 및 NUMA에서의 로컬 액세스와 리모트 액세스가 조금 더 쉽게 이해될 것이다.
그렇다면, 무조건적으로 NUMA 아키텍처를 사용하면 되는걸까?
결론적으로, NUMA 아키텍처를 가장 효율적으로 사용하기 위해서는 리모트 액세스가 일어나지 않게 하며, 최대한 로컬 액세스를 통해 메모리 사용이 이루어질 수 있도록 조절하는 것이 가장 중요한 포인트이다.
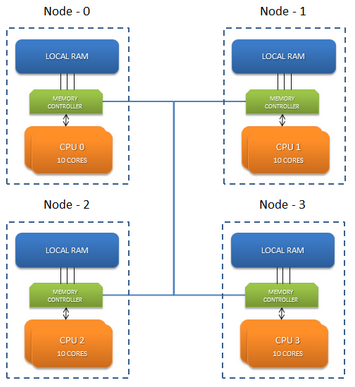
위 그림에서 CPU의 코어 별(프로세서)로 메모리가 할당되어 있으며 이를 Node 단위로 구분해놓았다. 위에서 언급했듯이 각 노드별 메모리의 액세스가 최대한 로컬 액세스로 이루어지도록 하는 것이 가장 중요한 포인트이며, 이를 NUMA 정책을 통해서 조절 할 수 있다.
NUMA 정책은 아래와 같이 크게 4가지 종류로 구분된다.
NUMA 정책
1. [ default ]
default 정책은 별도의 설정하지 않은 가장 기본적인 정책이며, 모든 프로세스에 적용된다.
현재 프로세스가 실행되고 있는 프로세서(CPU 코어)가 포함된 노드에서 먼저 메모리를 할당 받아 사용한다.
2. [ bind ]
bind 정책은, 특정 프로세스를 특정 노드에 바인딩 하여 해당 노드에서만 메모리를 할당받을 수 있게 조절하는 형식이다.
3. [ preferred ]
preferred 정책은 bind와 비슷하게 선호하는 노드를 설정하여 해당 노드에서 메모리를 우선적으로 할당 받을 수 있게 조절하는 형식이다.
4. [ interleaved ]
interleaved 정책은 다수의 노드에서 같은 비율의 메모리를 할당 받는 형식이다. RR(Round Robin) 식으로 다수의 노드로 부터 한번 씩 돌아가며 순서대로 메모리를 할당 받는다.
내 Linux 서버에 어떠한 정책이 설정되어 있는지는 "numactl" 명령어를 통해 확인이 가능하다. 해당 명령어를 사용하기 위해서는 해당 명령어 패키지 설치가 선행되어야 한다.
[root@ip-172-31-26-171 ~]# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
cpubind: 0
nodebind: 0
membind: 0
preferred:
아래의 명령어를 통해서는 NUMA의 노드와 노드별 할당된 CPU 번호 그리고 할당된 메모리 크기를 확인할 수 있다.
[root@ip-172-31-26-171 ~]# numactl -H
available: 1 nodes (0) <-- (1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <-- (2)
node 0 size: 31116 MB <-- (3)
node 0 free: 30431 MB
node distances: <-- (4)
node 0
0: 10
(1). NUMA 노드는 1개로 구성되어 있다.
(2). CPU는 총 16개로 이루어져있다. (프로세서 16개)
(3). 메모리의 크기
(4). 각 노드의 메모리에 접근하는 데 걸리는 시간으로 현재 는 노드가 한개 밖에 없기 때문에 비교가 불가능 하지만 만약 20이 있다면, 노드 0에서 1의 메모리에 접근하는데 2배의 시간이 걸리는 뜻이다.
"numactl" 명령어를 통해서 위와 같이 Node의 정보를 확인할 수 도 있으며, 아래의 옵션과 같이 사용하여 NUMA 정책을 변경하여 Node별 메모리 접근 방법을 다르게 설정 하여 메모리 관리를 진행할 수 있다.
--interleave=nodes, -i nodes
Set a memory interleave policy. Memory will be allocated using round robin on nodes. When memory cannot be allocated on the current interleave target fall back to other nodes.
--membind=nodes, -m nodes
Only allocate memory from nodes. Allocation will fail when there is not enough memory available on these nodes. nodes may be specified as noted above.
--cpunodebind=nodes, -N nodes
Only execute command on the CPUs of nodes. Note that nodes may consist of multiple CPUs. nodes may be specified as noted above.
--physcpubind=cpus, -C cpus
Only execute process on cpus. This accepts cpu numbers as shown in the processor fields of /proc/cpuinfo, or relative cpus as in relative to the current cpuset.
--localalloc, -l
Always allocate on the current node.
--preferred=node
Preferably allocate memory on node, but if memory cannot be allocated there fall back to other nodes. This option takes only a single node number. Relative notation may be used.
더 자세한 설명은 다음의 "numactl" man 페이지를 참고하면 된다.
numad 로 메모리 관리하기
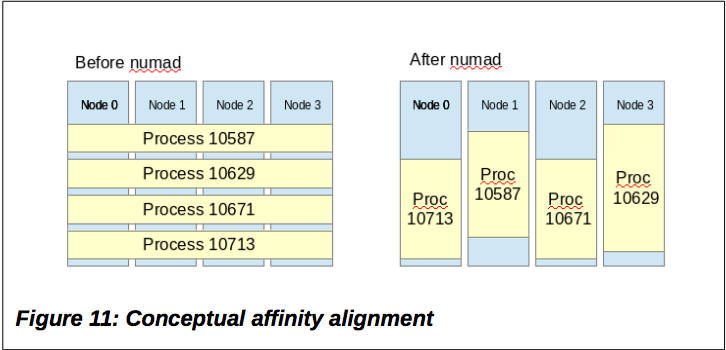
numad 는 백그라운드에서 동작하는 데몬으로 시스템상에서 프로세스들의 메모리 할당 과정을 최적화 하는 작업을 진행한다.
즉, numad를 잘 활용한다면 Linux 시스템에서 동작하는 수십개의 어플리케이션에 대한 메모리 할당 작업 관리를
매우 손쉽게 할 수 있다는 뜻이다.
다만, 만약 "Interleaved" 정책을 사용하여 Round-Robin 방식으로 노드 A의 메모리에 대하여 노드 B에서 A의 메모리를 할당받고 있는 프로세스가 존재하는 상황을 가정해보자. 해당 상황에서 numad를 실행시켜 새로운 프로세스 가 노드 B의 메모리를 모두 할당받게 되는 경우 노드 A와 B의 메모리간의 불균형이 일어날 수 있다.
아래는 numad와 관련한 문서이다. 필요시 참고하면 좋을 것 같다.
numad - Linux man page
numad - Red Hat
메모리 할당에서 커널 파라미터 "vm.zone_reclaim_mode"
[root@ip-172-31-26-171 ~]# cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 0 0 0 0 0 1 1 2
Node 0, zone DMA32 4 6 8 8 5 6 4 4 5 3 678
Node 0, zone Normal 186 502 786 443 136 84 56 21 16 25 6884
"vm.zone_reclaim_mode" 파라미터의 값에 따라 위와 같이 각각의 메모리 영역(DMA, DMA32, *Normal)에서 메모리가 부족할 때 다른 Node의 메모리 영역을 할당 할 수 있도록 해준다. 아래의 내용을 확인해보자.
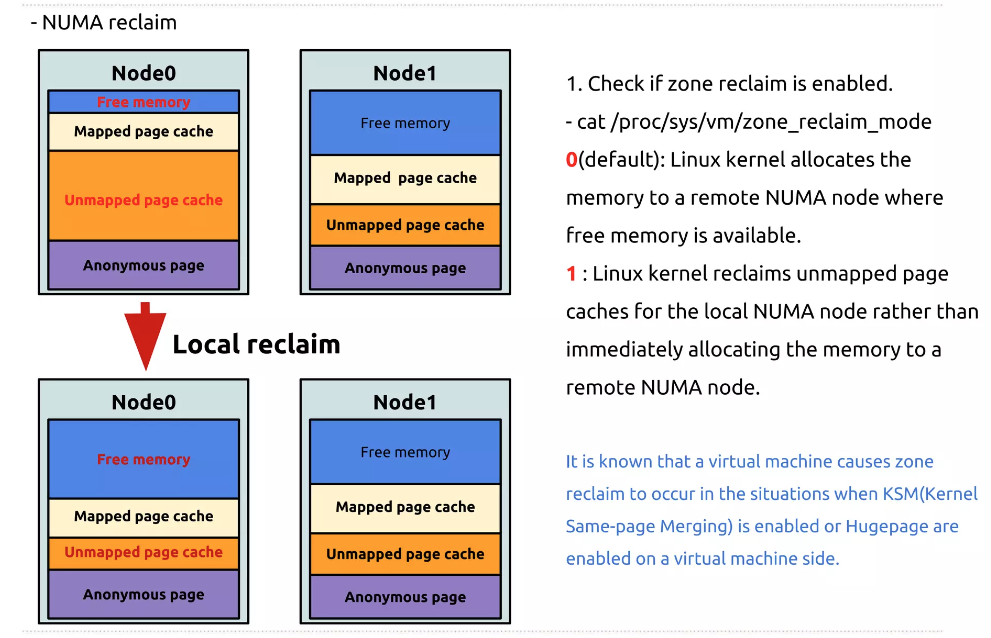
"vm.zone_reclaim_mode" 파라미터 값은 4개가 있지만 가장 중요한건 0과 1이다.
0은 disable로 default 값이며, 메모리가 부족할 시 해당 zone 안에서 재할당 하지 않고 다른 zone(다른 node에 할당된 메모리)에서 메모를 할당한다는 뜻이다.
1은 enable로 zone 안에서 재할당을 한다는 의미로, 메모리가 부족한 상황이 되면 해당 zone 안에서 최대한 재할당할 수 있도록 한다.
따라서, I/O 성능이 중요한 경우 Page Cache를 확보하기 위하여 메모리를 다른 영역에서 가져 오도록 vm.zone_reclaim_mode 값을 "0" 으로 설정한다.
반대로 로컬 메모리에 대한 액세스가 더 중요한 경우, vm.zone_reclaim_mode 값을 "1"로 설정하여 동일한 노드에서 메모리를 할당받게 해준다.
해당 글에서 NUMA 아키텍처와 관련한 정말 기본적인 개념들을 다루어 보았다.
Linux 시스템에서 운영하는 서비스의 워크로드에 대하여 극한의 성능 튜닝을 원한다면 반드시 확인해야할 부분이기 때문에
해당 글을 작성해보았으며, 한번쯤은 정리해 둘 필요가 있다고 느끼었다.
기회가 된다면, 해당글의 시리즈 편으로 실제 프로세스에 대한 메모리 할당 정책을 변경하여, numactl 및 numad를 적용 그리고 메모리가 실제 어떻게 할당되는지 확인하는 테스트를 진행해보려고 한다.




댓글