오늘은 멜론 TOP100 차트를 이용해서 아래와 같은 웹스크랩핑(Web scraping)을 해보려고 한다.
## Melon100 Chart
* 100곡의 노래의 제목과 SongID 추출해서 list에 저장하기
* 100곡 노래의 상세정보를 추출해서 list와 dict에 저장해서 json 파일로 저장하기
* json 파일을 load하여 Pandas의 DataFrame에 저장하기
* DataFrame 객체를 DB의 Table에 저장하기- Melon top100 차트에 연결하기
url = 'https://www.melon.com/chart/index.htm'
req_header_dict = {
# 요청헤더 : 브라우저정보
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
res = requests.get(url, headers=req_header_dict)
print(res.status_code)
200 # 정상- if res.ok 이면 해당 url의 html parsing
if res.ok:
html = res.text
#html 전체 소스보기
#print(html)
soup = BeautifulSoup(html, 'html.parser')
#html parsing
#print(soup)- parsing 한 HTML중 노래에 대한 정보만 담은 tag만 select하고 싶다.


크롬 개발자 모드(F12)에서 노래정보를 담은 <div>tb_list</div>에서<a tag>를 찾을 수 있다.
<a tag>만 select해서 print해보자.
#parsing한 html중 곡 에대한 정보를 담음 태그만 조회!!
a_tags = soup.select("div#tb_list tr a[href*='playSong']")
#print(a_tags)- playsong이 있는 <a></a>를 enumerate하여 dict형식으로 만들어준다.
song_list = []
for idx, a_tag in enumerate(a_tags,1):
#노래 1곡의 정보를 저장할 dict 선언
song_dict = {}
#노래 제목 갖고오기
song_title = a_tag.text
song_dict['song_title'] = song_title
print(song_dict)
- songid를 찾아보자
#a태그의 href 속성의 값을 추출하기 javascript:melon.play.playSong('1000002721',34535898);
href_value = a_tag['href']
#Song ID를 찾기 위한 정규표현식
matched = re.search(r'(\d+)\);', href_value)
print(matched)<re.Match object; span=(44, 54), match='34599917);'>
if matched 일때
if matched:
song_id = matched.group(1) # group(0) : 34535898); group(1) : 34535898
song_dict['song_id'] = song_id
#print(song_id)
song_detail_url = f'https://www.melon.com/song/detail.htm?songId={song_id}'
song_dict['song_detail_url'] = song_detail_url
song_list.append(song_dict)
print(len(song_list))
print(song_list[0]){'song_title': '언제나 사랑해', 'song_id': '34599917', 'song_detail_url': 'https://www.melon.com/song/detail.htm?songId=34599917'}이제 멜론 top100 리스트에서 곡의 순위대로 곡의 'song_title', 'song_id', 'song_detail_url'을 딕셔너리형태로 리스트에 저장하여 편하게 볼 수 있다.
아래에 원래 코드를 올려놓았다. song_list을 확인해보기위해 3번째까지 슬라이싱해주었다.
song_list = []
for idx, a_tag in enumerate(a_tags,1):
#노래 1곡의 정보를 저장할 dict 선언
song_dict = {}
#노래 제목 갖고오기 <a href="">노래제목</a>
song_title = a_tag.text
song_dict['song_title'] = song_title
#print(song_dict)
#a태그의 href 속성의 값을 추출하기 javascript:melon.play.playSong('1000002721',34535898);
href_value = a_tag['href']
#Song ID를 찾기 위한 정규표현식
matched = re.search(r'(\d+)\);', href_value)
#print(matched)
if matched:
song_id = matched.group(1) # group(0) : 34535898); group(1) : 34535898
song_dict['song_id'] = song_id
#print(song_id)
song_detail_url = f'https://www.melon.com/song/detail.htm?songId={song_id}'
song_dict['song_detail_url'] = song_detail_url
song_list.append(song_dict)
print(len(song_list))
print(song_list[:3])100
[{'song_title': '사랑은 늘 도망가', 'song_id': '34061322', 'song_detail_url': 'https://www.melon.com/song/detail.htm?songId=34061322'},
{'song_title': '취중고백', 'song_id': '34431086', 'song_detail_url': 'https://www.melon.com/song/detail.htm?songId=34431086'},
{'song_title': '호랑수월가', 'song_id': '34535898', 'song_detail_url': 'https://www.melon.com/song/detail.htm?songId=34535898'}]순서
1.100곡의 노래의 제목과 SongID 추출해서 list에 저장하기
2.100곡 노래의 상세정보를 추출해서 list와 dict에 저장해서 json 파일로 저장하기
이제 리스트한 100곡의 노래에서 상세정보를 추출한 뒤 json 파일로 저장해보자
- 노래에대한 상세정보를 넣을 리스트를 만들어주자
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.melon.com/chart/index.htm'
req_header_dict = {
# 요청헤더 : 브라우저정보
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
res = requests.get(url, headers=req_header_dict)
print(res.status_code)
song_detail_list = []
for idx, song in enumerate(song_list,1):- 이후 위의 for문을 사용하여 상세정보를 리스트에 넣어주자!
-for문에 어떠한 내용이 들어가야할까? : 곡에 대한 상세정보가 들어가야한다. 즉! 웹에서 곡에대한 상세정보를 갖고 있는 tag를 찾아야한다.
멜론 사이트에서 차트에 올라온 앨범을 선택하고 곡정보를 선택하면 위와같은 정보를 얻을 수 있다.
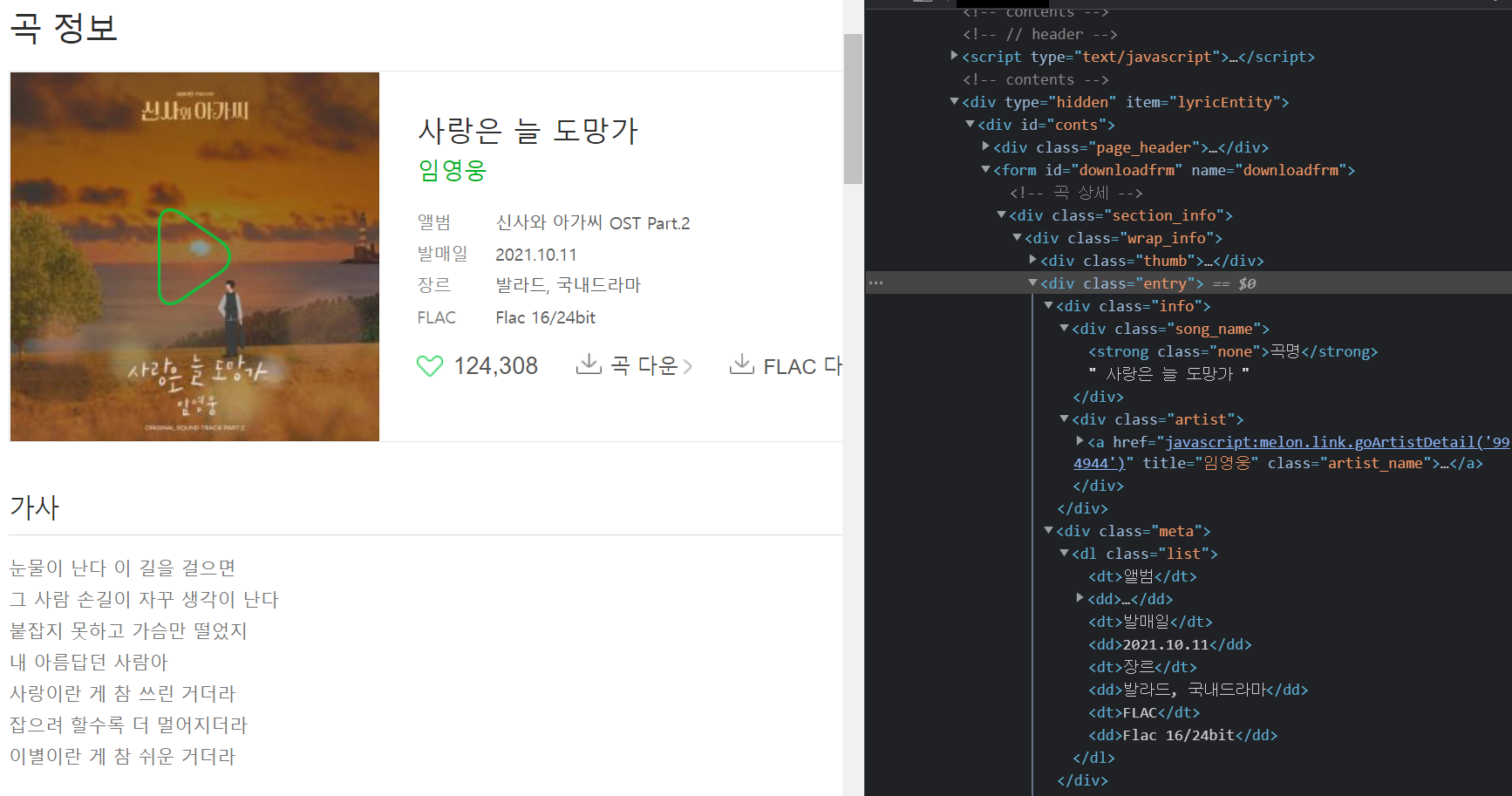

위 정보를 바탕으로 아래와 같이 코드를 짜보자
song_detail_list = []
for idx, song in enumerate(song_list[:3],1): # 결과가 매번 100개씩출력되어서 3순위까지 임시로 슬라이싱
#노래 1곡의 상세정보를 저장할 dict
song_detail_dict = {}
song_detail_url = song['song_detail_url']
res = requests.get(song_detail_url, headers=req_header_dict)
#print(res.status_code)
if res.ok:
soup = BeautifulSoup(res.text, 'html.parser')
#print(idx,song['song_title'])
song_detail_dict['곡명'] = song['song_title']
#노래 1곡의 상세정보에 '곡명'을 찾아 주었다.
#다음으로 상세정보 '가수'를 찾는다
singer = soup.select("a[href*='goArtistDetail'] span")
#print(singer)
if singer:
song_detail_dict['가수'] = singer[0].text # singer리스트에서 0번째 순서에 해당하는것을 text로 뽑으면 이름이다.
#print(singer[0].text)
#다음으로 div.meta에서 dd로 끝나는 값들을 넣어준다
song_di = soup.select("div.meta dd")
#print(song_di)
if song_di:
song_detail_dict['앨범'] = song_di[0].text
song_detail_dict['발매일'] = song_di[1].text
song_detail_dict['장르'] = song_di[2].text
song_detail_dict['FLAC'] = song_di[3].text
song_detail_list.append(song_detail_dict)
print(song_detail_list)print(song_detail_list) 결과
[{'곡명': '취중고백', '가수': '김민석 (멜로망스)', '앨범': '취중고백', '발매일': '2021.12.19', '장르': '발라드'},
{'곡명': '호랑수월가', '가수': '탑현', '앨범': '호랑수월가', '발매일': '2022.01.15', '장르': '발라드'},
{'곡명': '사랑은 늘 도망가', '가수': '임영웅', '앨범': '신사와 아가씨 OST Part.2', '발매일': '2021.10.11', '장르': '발라드, 국내드라마'}]
여기까지,
곡명, 가수, 앨범, 발매일, 장르, FLAC 6가지에 대한 상세정보를 웹페이지에서 가져와 보았다.
더 나아가서 좋아요 수와 가사까지 추가해보자!
- 좋아요수에 대한 정보를 어디서 갖고와야할까 ?

좋아요 수에 대한 정보를 갖고오기 위해
평소처럼 해당 곡을 나타내는 웹페이지에서 개발자모드로 들어가 찾아내려고했다.
손쉽게 좋아요 수로 보이는 정보를 얻을 수 있었고 아래코드를 통해 좋아요를 가져오려고 했다.
#첫번째
song_like = soup.select("div.cnt span")
[]
[]
[]
#두번째
song_like = soup.select("span.cnt span")
[<span class="none">총건수</span>, <span class="eng">FLAC</span>, <span class="none">총건수</span>, <span class="none">총건수</span>, <span class="none">총건수</span>, <span class="none">총건수</span>, <span class="none">총건수</span>, <span class="none">총건수</span>, <span class="none">총건수</span>]그러나 좋아요에 대한 데이터를 불러올 수 없었다.
ajax를 통해 웹페이지에 좋아요수를 반영하고 있는것 아닐까? 생각해보았고 바로 찾아보았다.
개발자 모드에서 ->Network -> Fetch/XHR 에서 바로 정보를 찾을 수 있었다.
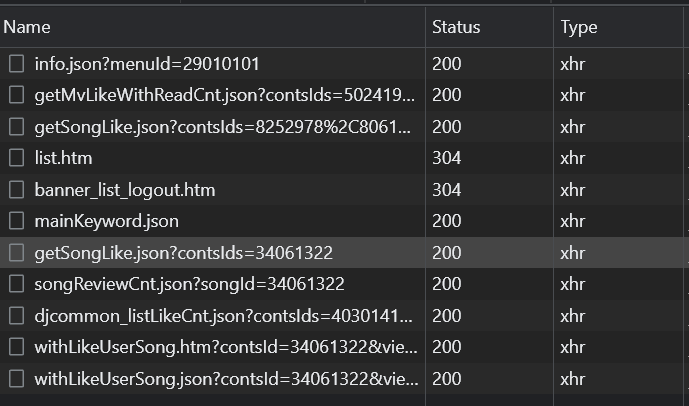
해당 정보를 눌러보면 아래와 같은 데이터를 얻을 수 있다.
{"contsLike":[{"CONTSID":34061322,"LIKEYN":"N","SUMMCNT":124329}],"httpDomain":"http://www.melon.com","httpsDomain":"https://www.melon.com","staticDomain":"https://static.melon.co.kr"}좋아요 정보를 추가하는 코드
song_id = song['song_id'] #song_id = matched.group(1) 갖고 와서 곡별 고유 id를 이용하자
like_url = f'https://www.melon.com/commonlike/getSongLike.json?contsIds={song_id}'
like_res = requests.get(like_url, headers=req_header_dict)
if like_res.ok:
song_detail_dict['좋아요'] = like_res.json()['contsLike'][0]['SUMMCNT']
#{'contsLike': [{'CONTSID': 34061322, 'LIKEYN': 'N', 'SUMMCNT': 124335}], 'httpDomain': 'http://www.melon.com', 'httpsDomain': 'https://www.melon.com', 'staticDomain': 'https://static.melon.co.kr'}
#좋아요 수 추가 완료좋아요수도 추가했으니 마지막으로 가사도 추가해보자!!

song_lyric = soup.select("div#d_video_summary")
if song_lyric:
song_detail_dict['가사'] = song_lyric[0].text
song_detail_list.append(song_detail_dict)
print(song_detail_list)마지막으로 song_lyric을 만들어서 추가해준 뒤 그동안 만들었던 dict파일을 list에 더해줘서
song_detail_list을 출력했다.
[{'곡명': '취중고백', '가수': '김민석 (멜로망스)', '앨범': '취중고백', '발매일': '2021.12.19',
'장르': '발라드', 'FLAC': 'Flac 16bit', '좋아요': 69231,
'가사': '\r\n\t\t\t\t\t\t\t뭐하고 있었니 늦었지만잠시 나올래너의 집 골목에 있는놀이터에 앉아 있어친구들 만나서 오랜만에술을 좀 했는데자꾸만 니 얼굴 떠올라무작정 달려왔어이 맘 모르겠니요즘 난 미친 사람처럼너만 생각해대책없이 네가 점점 좋아져아냐 안 취했어 진짜야널 정말 사랑해눈물이 날만큼 원하고 있어정말로 몰랐니가끔 전화해 장난치듯주말엔 뭐할거냐며너의 관심 끌던 나를그리고 한번씩 누나 주려 샀는데너 그냥 준다고생색 낸 선물도 너 때문에 산거야이 맘 모르겠니요즘 난 미친 사람처럼너만 생각해대책없이 네가 점점 좋아져아냐 안 취했어 진짜야널 정말 사랑해진심이야 믿어줘갑자기 이런 말 놀랐다면 미안해부담이 되는게 당연해이해해 널하지만 내 고백도 이해해 주겠니 oh지금 당장 대답하진마나와 일주일만 사귀어줄래후회없이 잘 해주고 싶은데그 후에도 니가 싫다면나 그때 포기할게귀찮게 안할게 혼자 아플게진심이야 너를 사랑하고 있어\n'},모든 결과가 올바르게 출력이 되었지만 왜인지모르게 가사에 역슬래시로 된 문구도 같이 출력이되었다.
song_lyric = soup.select("div#d_video_summary")
if song_lyric:
song_detail_dict['가사'] = song_lyric[0].text
# \r\n\t 특수문자를 찾아주는 Pattern 객체생성
pattern = re.compile(r'[\r\n\t]')
# \r\n\t 특수문자를 ''(empty string)으로 대체(substitute)해라
lyric = pattern.sub('', song_detail_dict['가사'].strip())
else:
lyric = '' #가사가 없는경우
song_detail_dict['가사'] = lyric{'곡명': '취중고백', '가수': '김민석 (멜로망스)', '앨범': '취중고백', '발매일': '2021.12.19',
'장르': '발라드', 'FLAC': 'Flac 16bit', '좋아요': 69232,
'가사': '뭐하고 있었니 늦었지만잠시 나올래너의 집 골목에 있는놀이터에 앉아 있어친구들 만나서 오랜만에술을 좀 했는데자꾸만 니 얼굴 떠올라무작정 달려왔어이 맘 모르겠니요즘 난 미친 사람처럼너만 생각해대책없이 네가 점점 좋아져아냐 안 취했어 진짜야널 정말 사랑해눈물이 날만큼 원하고 있어정말로 몰랐니가끔 전화해 장난치듯주말엔 뭐할거냐며너의 관심 끌던 나를그리고 한번씩 누나 주려 샀는데너 그냥 준다고생색 낸 선물도 너 때문에 산거야이 맘 모르겠니요즘 난 미친 사람처럼너만 생각해대책없이 네가 점점 좋아져아냐 안 취했어 진짜야널 정말 사랑해진심이야 믿어줘갑자기 이런 말 놀랐다면 미안해부담이 되는게 당연해이해해 널하지만 내 고백도 이해해 주겠니 oh지금 당장 대답하진마나와 일주일만 사귀어줄래후회없이 잘 해주고 싶은데그 후에도 니가 싫다면나 그때 포기할게귀찮게 안할게 혼자 아플게진심이야 너를 사랑하고 있어'},잘 출력되는 것을 확인 할 수 있다.
글을 쓰다보니까 길어져서 list파일을 json파일로 저장하여 load하는것은 2편에 써보겠다.

댓글